Constrained generation with JSON mode
JSON Mode enables the LLM to produce a JSON-formatted responses, useful when you want to integrate the LLM with other systems that expect a reliably parsable output.
You can request for a JSON formatted output by setting the response_format = {"type": "json_object"} parameter in the POST request to the LLM. You can optionally provide a schema by setting the response_format = {"type": "json_object", "schema": <schema>} parameter. If you don't provide a schema, the LLM outputs any JSON object that it sees fit. JSON Schema is a declarative language for defining the structure of JSON objects. You can learn more about JSON Schema here.
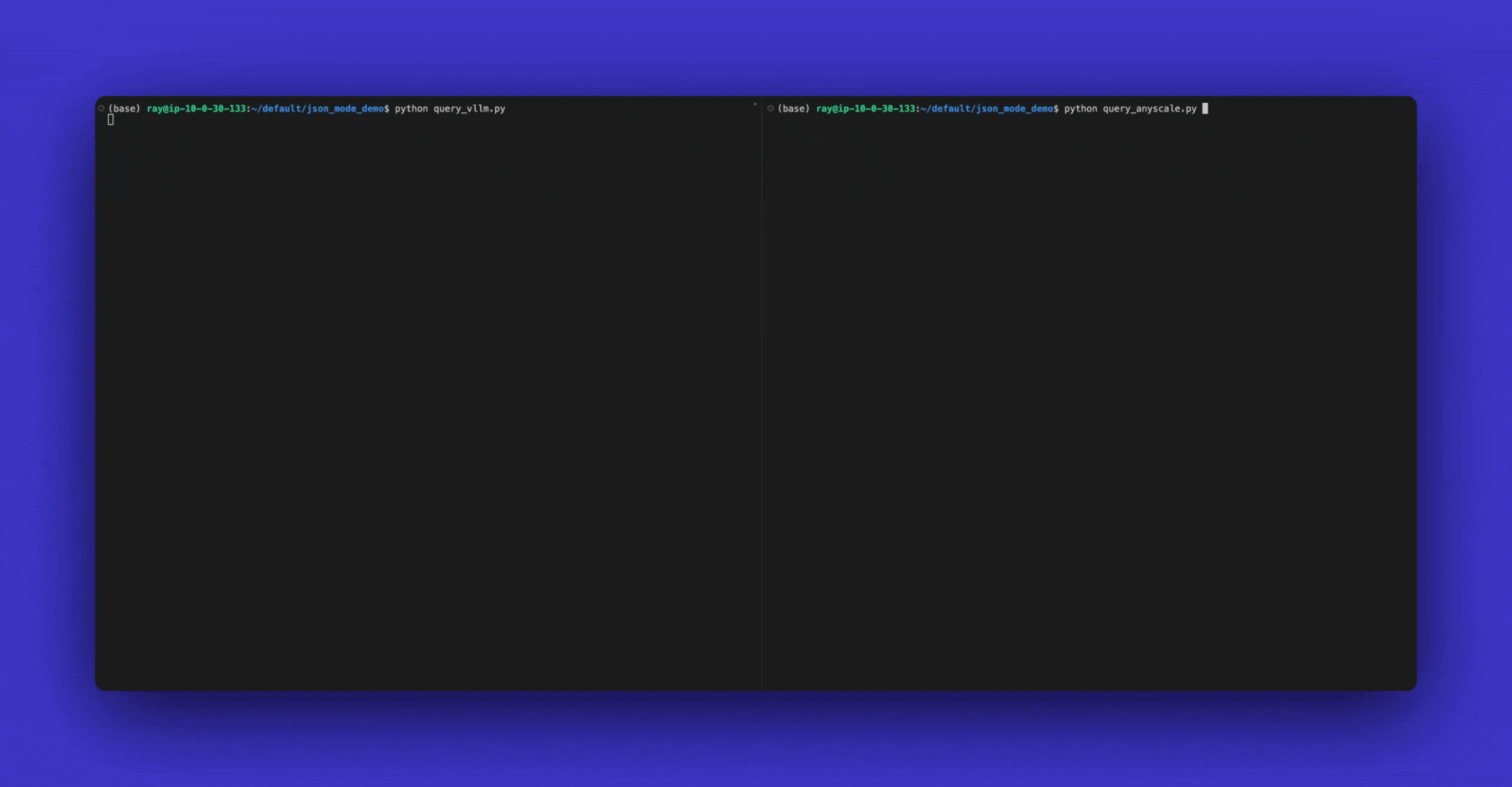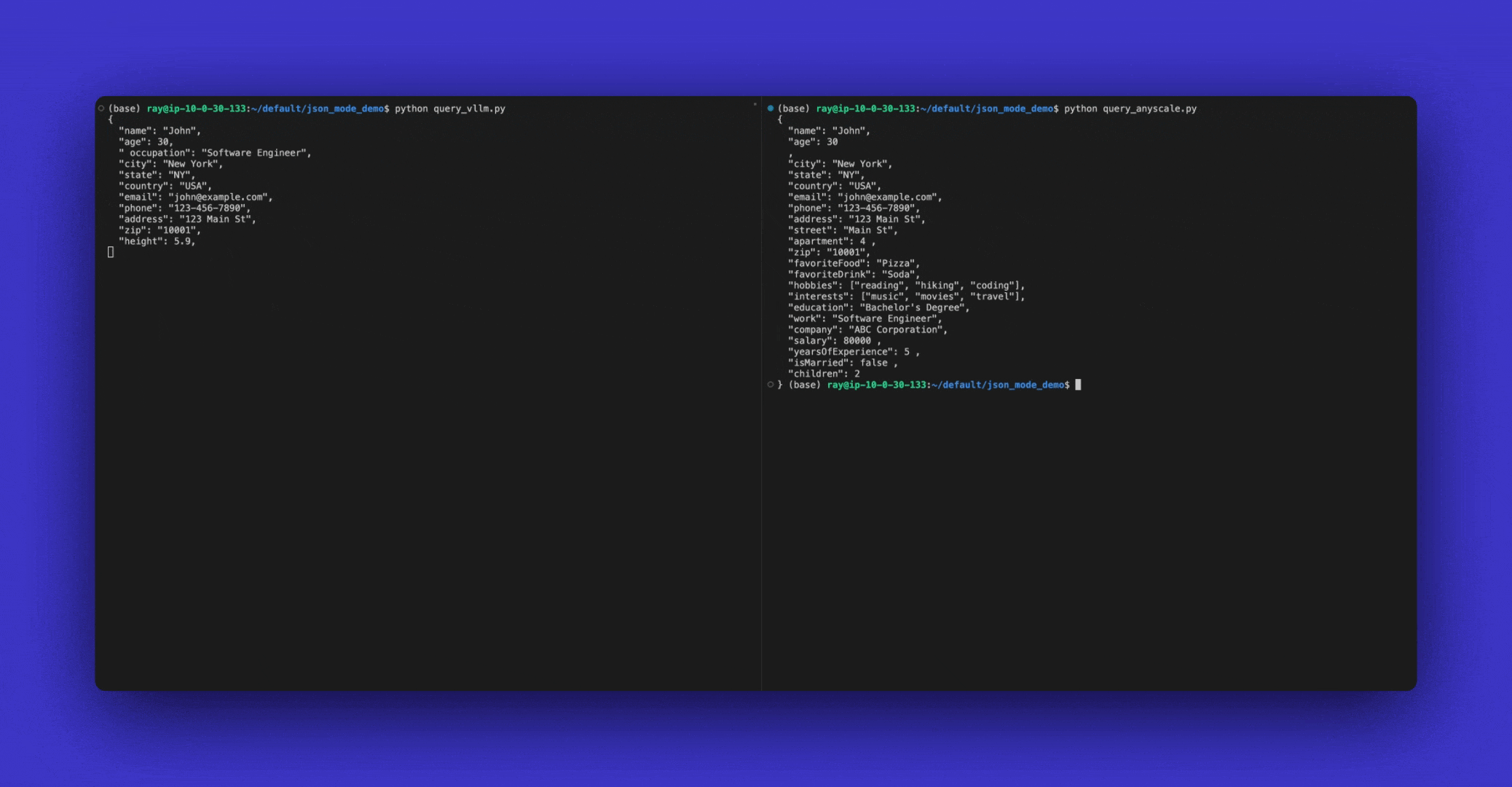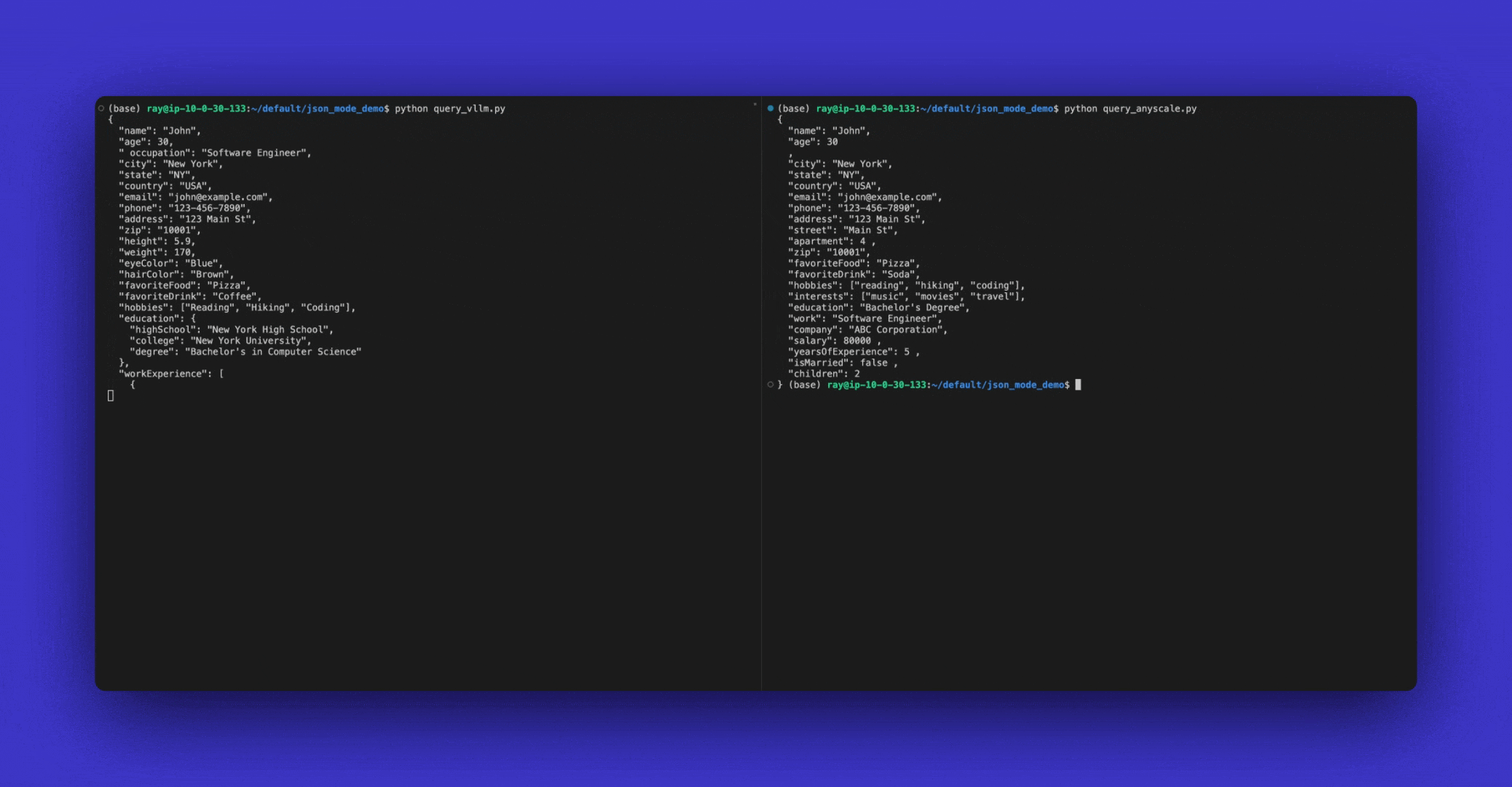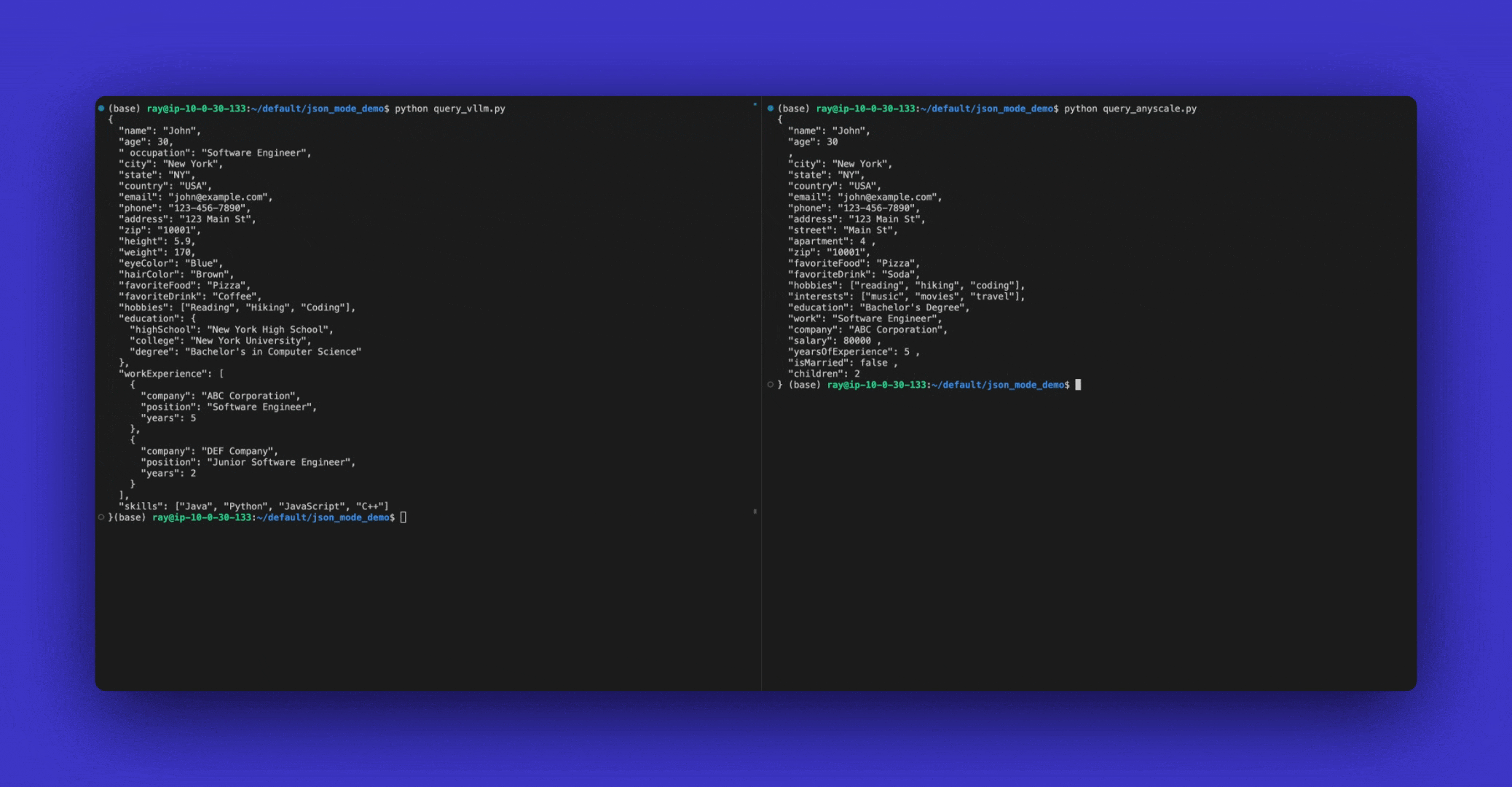
JSON Mode is currently only supported in vLLM. On Anyscale we have a proprietary implementation of JSON Mode that is faster and more reliable.
top_p and top_k sampling parameters are incompatible with JSON mode.
Not explicitly instructing the model to output in JSON is prone to outputting a string of whitespaces before and after the JSON object, costing more tokens and time. To prevent this issue, RayLLM raises an error if the sub-string json is not found in the message list (not case-sensitive).
Example query in JSON mode
Here is how you can query an LLM with JSON Mode enabled (example is running on meta-llama/Meta-Llama-3-8B-Instruct):
- cURL
- Python
- OpenAI Python SDK
curl "$ANYSCALE_BASE_URL/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $ANYSCALE_API_KEY" \
-d '{
"model": "meta-llama/Meta-Llama-3-8B-Instruct",
"messages": [{"role": "system", "content": "You are a helpful assistant that outputs in JSON."}, {"role": "user", "content": "Who won the world series in 2020"}],
"response_format": {"type": "json_object", "schema": {"type": "object", "properties": {"team_name": {"type": "string"}}, "required": ["team_name"]}},
"temperature": 0.7
}'
import os
import requests
s = requests.Session()
api_base = os.getenv("ANYSCALE_BASE_URL")
token = os.getenv("ANYSCALE_API_KEY")
url = f"{api_base}/chat/completions"
body = {
"model": "meta-llama/Meta-Llama-3-8B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant that outputs in JSON."},
{"role": "user", "content": "Who won the world series in 2020"}
],
"response_format": {
"type": "json_object",
"schema": {
"type": "object",
"properties": {
"team_name": {"type": "string"}
},
"required": ["team_name"]
},
},
"temperature": 0.7
}
with s.post(url, headers={"Authorization": f"Bearer {token}"}, json=body) as resp:
print(resp.json())
import openai
client = openai.OpenAI(
base_url = "<PUT_YOUR_BASE_URL>",
api_key = "FAKE_API_KEY")
# Note: not all arguments are currently supported and will be ignored by the backend.
chat_completion = client.chat.completions.create(
model="meta-llama/Meta-Llama-3-8B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant that outputs in JSON."},
{"role": "user", "content": "Who won the world series in 2020"}
],
response_format={
"type": "json_object",
"schema": {
"type": "object",
"properties": {
"team_name": {"type": "string"}
},
"required": ["team_name"]
},
},
temperature=0.7
)
print(chat_completion.model_dump())
The output will look like:
{'choices': [{'finish_reason': 'stop',
'index': 0,
'message': {'content': '{"team_name": "Los Angeles Dodgers"}',
'function_call': None,
'role': 'assistant',
'tool_calls': None}}],
'created': 1701933511,
'id': 'meta-llama/Meta-Llama-3-8B-Instruct-4-7sX-l4EqKMl0FxZu7f5HQ8DXIKMIQgCkT1sWGLwn8',
'model': 'meta-llama/Meta-Llama-3-8B-Instruct',
'object': 'text_completion',
'system_fingerprint': None,
'usage': {'completion_tokens': 16, 'prompt_tokens': 30, 'total_tokens': 46}}
Streaming JSON mode completions
You can also use the streaming API to get JSON mode completions. Here's an example using the Python SDK:
import openai
client = openai.OpenAI(
base_url = "<PUT_YOUR_BASE_URL>",
api_key = "FAKE_API_KEY")
# Note: not all arguments are currently supported and will be ignored by the backend.
chat_completion = client.chat.completions.create(
model="meta-llama/Meta-Llama-3-8B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant that outputs in JSON."},
{"role": "user", "content": "Who won the world series in 2020"}
],
response_format={
"type": "json_object",
"schema": {
"type": "object",
"properties": {
"team_name": {"type": "string"}
},
"required": ["team_name"]
},
},
temperature=0.7,
stream=True
)
for chunk in chat_completion:
text = chunk.choices[0].delta.content
if text:
print(text, end="")
Enable JSON mode in RayLLM
Enable JSON mode in the llm_config by setting enabled to true in the json_mode entry:
model_loading_config:
model_id: meta-llama/Meta-Llama-3-8B-Instruct
...
...
json_mode:
enabled: true
...
that you cannot use JSON mode and multi-LoRA on the same model.
Anyscale's JSON Mode vs. other open-source implementations
This part, first explains the general algorithmic paradigms that are used to enable constrained generation in LLMs. Then, it explains how Anyscale's JSON Mode fits into this landscape and how it compares to some other existing approaches:
Algorithmic paradigms for constrained generation in LLMs
Constrained generation in LLMs is roughly based on one of the two following algorithm paradigms:
Finite-state based algorithms
This refers to algorithms that given a schema, they compile it to a finite-state machine (FSM) first and use it to guide the generation process. This includes all possible decision points that may or may not be explored during generation.
For example outlines or SGLang both follow this paradigm. The rough sketch of the algorithm is as follows:
-
Parse the schema and compile it to a character-level FSM: In this step, these methods often first compile the input schema (expressed as JSON schema) to a more compact representation (for example Regex) and then convert this intermediary generic representation to a character-level FSM. This FSM basically is a graph that has a root, each node represents a valid partial generation and the traversal from the root tells you all the valid completions of the schema.
-
Convert the character-level FSM to token-level FSM: Language models do not understand characters, they understand tokens. So, the next step is to convert the character-level FSM to a token-level FSM. The output of this stage, is a new graph where edges show the transitions because of as a result of choosing tokens (instead of characters). After this stage, you can play tricks like FSM compression to make the FSM more compact and faster to traverse during generation.
-
Generation: In this stage, the FSM is traversed and when there are multiple traversal options, the LLM is queries to choose the best token to continue the traversal.
This blog post has a much more in-depth explanation of this approach.
Token-tree traversal algorithms (T3)
In contrast to the first approach that does all the preprocessing before the generation, this approach interleaves the generation and token-tree traversal together. In the first approach, a lot of compute is spent on constructing the fine details of an FSM that most likely will not be traversed. In other words, it can become wasteful if you are planning to traverse it only once and move on to another schema. The T3 algorithms on the other hand, do not construct the FSM beforehand, instead they construct the relevant parts of it on-the-fly during generation, saving the cold-start time and memory required in FSM-based algorithms. Example of a library that follows this approach is LMFE.
FSM-based approaches are more suitable for scenarios where you have a fixed schema that you want to apply to many prompts and the cold-start time is tolerable. The cold-start time in FSM-based approaches gets much worse, with large LLM vocabulary sizes and with the complexity of the schemas. In contrast, T3 approach is more suitable for online inference on LLMs where you cannot predict the schema beforehand.
Anyscale's JSON Mode
vLLM by default supports JSON Mode with outlines and LMFE backends. On Anyscale, we have developed a proprietary variation in vLLM based on the T3 approach. Our implementation has the following value-adds on top of LMFE method in open-source vLLM:
- Support formal grammars in form of GBNF: The backend uses GBNF to define the traversal algorithm, and JSON schema is converted to GBNF as input. This allows for more complex schemas to be defined and used in the backend.
- Fault-tolerance on bad schema: Sometimes certain schema edge-cases in JSON are not supported and as a result the backend might break. Our implementation is fault-tolerant to such cases and can recover from them.
- Overlapping decode with token-tree traversal: In parallel to doing decoding on GPUs, we can compute the logits masks computation on all items inside the batch on CPUs. This allows to not waste GPU time on the token-tree traversal.
- Efficient token-tree traversal done in C++ for speed: The heavy-lifting is done in C++ for speed.
- Cache-aware traversal for faster generation: On the backend we have implemented multiple caches to avoid redundant computations during mask computation.
- Distributed logit mask generation for batched requests: We used Ray to distribute the logit processors, so that on batched inputs we can compute the logit masks in parallel.
- Low latency overhead on "non-JSON" requests: If you batch requests that are not constrained with those that are, the overhead of constrained requests will trickle down to the non-constrained ones. Our implementation has a low overhead on non-constrained requests.
Tool calling and function calling
Since JSON mode makes an LLM's output parsable, it can be used to build tool calling (also called function calling) into an LLM application. Tool calling is a feature where a user provides an LLM with a prompt and a set of functions, their parameters, and descriptions of their behavior. The LLM can ask the user to call one of the functions and incorporate the output into its response.
See the Deploy LLM template or this GitHub sample to see an end-to-end example of using tool calling with RayLLM.