Import custom models
This version of the Anyscale docs is deprecated. Go to the latest version for up to date information.
In addition to the set of built-in supported models, you can import your own custom models for serving and fine-tuning. Anyscale Private Endpoints runs vLLM-compatible models using a performance-enhanced version of RayLLM. As a result, you must provide a RayLLM generation field for any imported models. Follow the guide for instructions on how to import custom models.
1. Connect to Anyscale Cloud
Upload the model and tokenizer into the cloud storage bucket connected to an Anyscale Cloud. Ensure that the Amazon S3 or Google Cloud Storage permissions allow Anyscale to access all relevant model files.
2. Add model details
Submit the following for the custom model:
- Model ID - Assign a unique name for the model.
- Remote URI - Specify the bucket URI such as
s3://BUCKET_NAME/MODEL_FOLDERorgs://BUCKET_NAME/MODEL_FOLDER. - Number of parameters - Indicate the size of the model in billions of parameters. For example,
70for 70 billion parameters. - Generation configuration - Define a YAML file for how the engine should format prompts and what sequences trigger it to stop generating.
Generation configuration examples
For chat-based large language models (LLMs), the training data follows a unique format to identify different roles in a conversation. Endpoints then uses this prompt_format during inference to convert the user's API input into a recognizable pattern for the LLM. The stopping_sequences parameter defines when the model should stop generating. Different models have varying formats, so make sure to match the specific model's requirements.
You can find a list of pre-defined configurations in the open source ray-llm repository, or you can define your own and contribute it to the repo. Below are some examples for common chat models.
Llama models
prompt_format:
system: "<<SYS>>\n{instruction}\n<</SYS>>\n\n"
assistant: " {instruction} </s><s>"
trailing_assistant: ""
user: "[INST] {system}{instruction} [/INST]"
system_in_user: true
default_system_message: ""
stopping_sequences: []
Mistral models
prompt_format:
system: "{instruction} + "
assistant: "{instruction}</s> "
trailing_assistant: ""
user: "[INST] {system}{instruction} [/INST]"
system_in_user: true
default_system_message: "Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity."
stopping_sequences: []
Falcon models
prompt_format:
system: "<|prefix_begin|>{instruction}<|prefix_end|>"
assistant: "<|assistant|>{instruction}<|endoftext|>"
trailing_assistant: "<|assistant|>"
user: "<|prompter|>{instruction}<|endoftext|>"
default_system_message: "Below are a series of dialogues between various people and an AI assistant. The AI tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable. The assistant is happy to help with almost anything, and will do its best to understand exactly what is needed. It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer. That said, the assistant is practical and really does its best, and doesn't let caution get too much in the way of being useful."
stopping_sequences: ["<|prompter|>", "<|assistant|>", "<|endoftext|>"]
3. Use the custom model
Deploy to an endpoint
Navigate to the Endpoints servers page and select Create. Then, on the New Endpoint page, select the Anyscale Cloud and imported model to serve.
Start a fine-tuning job
Navigate to the Fine-tuning page and select New fine-tuning job. Then, select the Anyscale Cloud and imported model, and proceed with the fine-tuning instructions.
Quantized models
Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and/or activations with low-precision data types like 4-bit integer (int4) instead of the usual 16-bit floating point (float16). To serve a quantized model with cheaper hardware requirements to potentially lower inference costs, follow these additional steps:
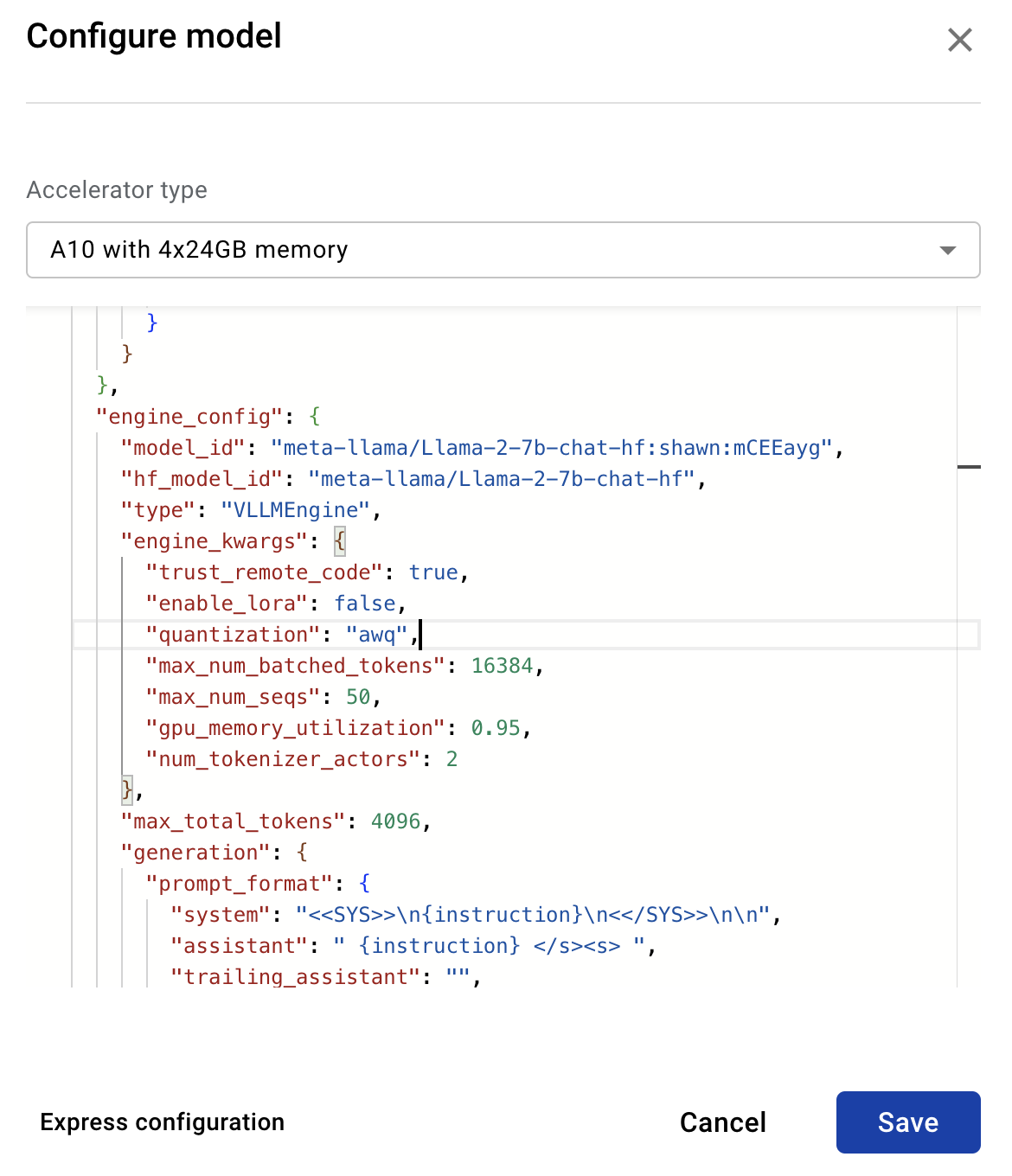
- After you deploy the model, navigate to the endpoint detail page.
- Under Deployed models select Configure on the imported model.
- Select Advanced configuration.
- In the
engine_kwargsblock, add either"quantization": "awq"orquantization: squeezellmbased on the model's quantization technique.
Supported models
Anyscale is continuously working to support a wide range of vLLM-compatible models. The current support includes versions of Llama-based and Mistral-based models, with ongoing efforts to expand this list.
| Endpoint Version | Supported Model |
|---|---|
| 0.3.1 | Llama-based: Yes Mistral-based (non-quantized): Yes Mistral-based (quantized): No |
| 0.3.2 | Llama-based: Yes Mistral-based(non-quantized): Yes Mistral-based (quantized): No |