Continue fine-tuning from a previous checkpointing
In this guide, we showcase how a checkpoint that was created earlier can be used as initialization for another round of fine-tuning. This allows us to sequentially combine fine-tuning on multiple datasets in order to get performance boost on the final task that we care about. You can even do pre-training + classification fine-tuning and change the tasks in between.
Anyscale supports both Full-parameter checkpoints, and LoRA-adapter checkpoints. However, don't combine the two by training a full-parameter model followed by a LoRA adaptation. Serving the resulting LoRA adapter requires the base full-parameter checkpoint. Unless you are fine-tuning many LoRA adaptors for different tasks, this serving architecture doesn't have the economical benefits of LoRA or the quality benefits of full-parameter. See Fine-Tuning with LoRA vs Full-parameter for more details.
Config parameters
In general, you can customize the initial weights in your fine-tuning run through two options in the YAML:
initial_base_model_ckpt_path: Path to the base model weights you wish to start withinitial_adapter_model_ckpt_path: Path to the adapter (LoRA) weights you wish to start with
Note that you can use the above parameters independent of one another. They can be a local cluster path, cloud storage path (s3:// or gs://), or a Hugging Face repo ({"repo_id": "my_org/my_model"}). Read the config docs for full details.
Example
You can find the config for this example on GitHub. To run this example, open the fine-tuning template in a workspace and run this command from the root of the template.
llmforge anyscale finetune training_configs/custom/meta-llama/Meta-Llama-3-8B/lora/continue_from_checkpoint.yaml
Running the above command will fine-tune on the GSM8k dataset. This example splits the dataset into two halves, each consisting of approximately 4,000 samples. The provided initial checkpoint has been trained on the first half and is already good at solving GSM8k. By running the above command, you continue fine-tuning from the provided checkpoint with the second half.
Note the following evaluation losses. The first three epochs of training where run on the first half of the GSM8k dataset. The second three epochs of training where run on the second half.
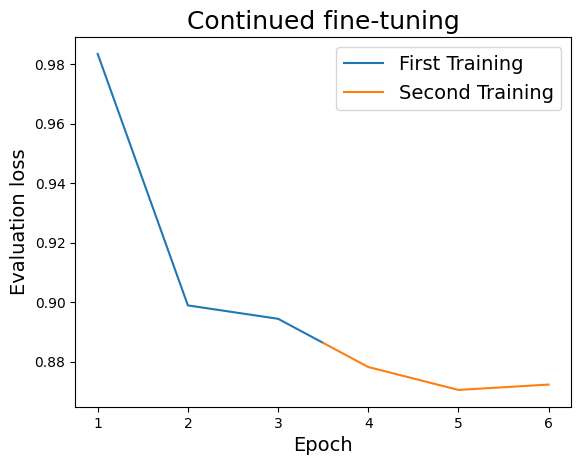
Note that on the first iteration of the second training (epoch 4), the evaluation loss starts off much lower than in the first training.
What and how are we fine-tuning?
The following is a snippet from the YAML file we use above.
model_id: meta-llama/Meta-Llama-3-8B-Instruct
initial_adapter_model_ckpt_path: s3://large-dl-models-mirror/finetuning_template/continued_ft_gsm8k_checkpoint
train_path: s3://large-dl-models-mirror/finetuning_template/train_2.jsonl
...
We fine-tune Llama 3 8B Instruct, but the initial weights of the LoRA adapter are loaded from our S3 mirror.
The train path (.../train_2.jsonl) points to the second part of the GSM8k dataset that we fine-tune on.
To continue the fine-tuning of a full-parameter checkpoint, configure initial_base_model_ckpt_path instead of initial_adapter_model_ckpt_path.
Things to Notice
When comparing the training and evaluation loss of the second (continued) fine-tuning with the first run, you'll notice that the values are lower. For instance, the checkpoint in the YAML has an evaluation loss of 0.8886. After continued fine-tuning, we achieve a checkpoint with an evaluation loss of 0.8668. It's important to note that the significance of such loss values varies greatly depending on the task at hand. A difference of 0.0218 may represent a substantial improvement for some tasks, while it may only be a minor improvement for others.
To determine whether continued fine-tuning is beneficial for your specific task, we recommend monitoring the training and evaluation loss during the fine-tuning process. This will help you assess the impact of the additional fine-tuning on your model's performance.
In general, finish with the dataset that is closest to what you want during inference. For example, if you are extending the context of the model beyond its native context length, you should start with the smallest context length end with the largest.