Preference Tuning With DPO
Alignment of LLMs has traditionally been broken down into two post-training stages: Supervised fine-tuning (SFT) followed by preference tuning (aka RLHF). Preference tuning is a powerful tool that can optimize LLMs towards complex preferences that cannot be easily captured through supervised fine-tuning.
This guide will focus on how you can do direct preference optimization (DPO) fine-tuning of open-source language models on Anyscale.
DPO is supported only with llmforge versions >= 0.5.3. You can see the full list of available versions and images here
Config parameters
You can see all the config options in the reference docs. For preference tuning in llmforge, you can simply specify the preference_tuning_config in your config YAML:
preference_tuning_config:
# beta parameter in DPO, controlling the amount of regularization
beta: 0.01
logprob_processor_scaling_config:
custom_resources:
accelerator_type:A10G: 0.001 # custom resource per worker.
# Runs reference model logp calculation on 4 GPUs
concurrency: 4
# Batch size per worker
batch_size: 2
beta:betais a parameter controlling the amount of regularization, typically set between 0 and 1. A higherbetaimplies that the trained model (output distribution) is closer to the reference model (output distribution), while the reference model is ignored asbetatends to zero. See the DPO paper for more details.logprob_processor_scaling_config: We calculate log probabilities for the chosen and rejected samples from the reference model for the DPO loss. Internally, this is implemented as aray.data.Dataset.map_batchesoperation.logprob_processor_scaling_configis the scaling config for the reference model. In the above example, we specify a batch size of 2 per reference model instance, with a custom resource label indicating that each reference model should be run on an A10G GPU. A total of 4 concurrent instances are used.
Our implementation of DPO can overlap model forward pass with reference model log probability calculation, while also decoupling the compute configuration of both. For example, you can run the reference model on smaller, cheaper A10G GPUs (since reference model is only used for inference) while running training on A100s.
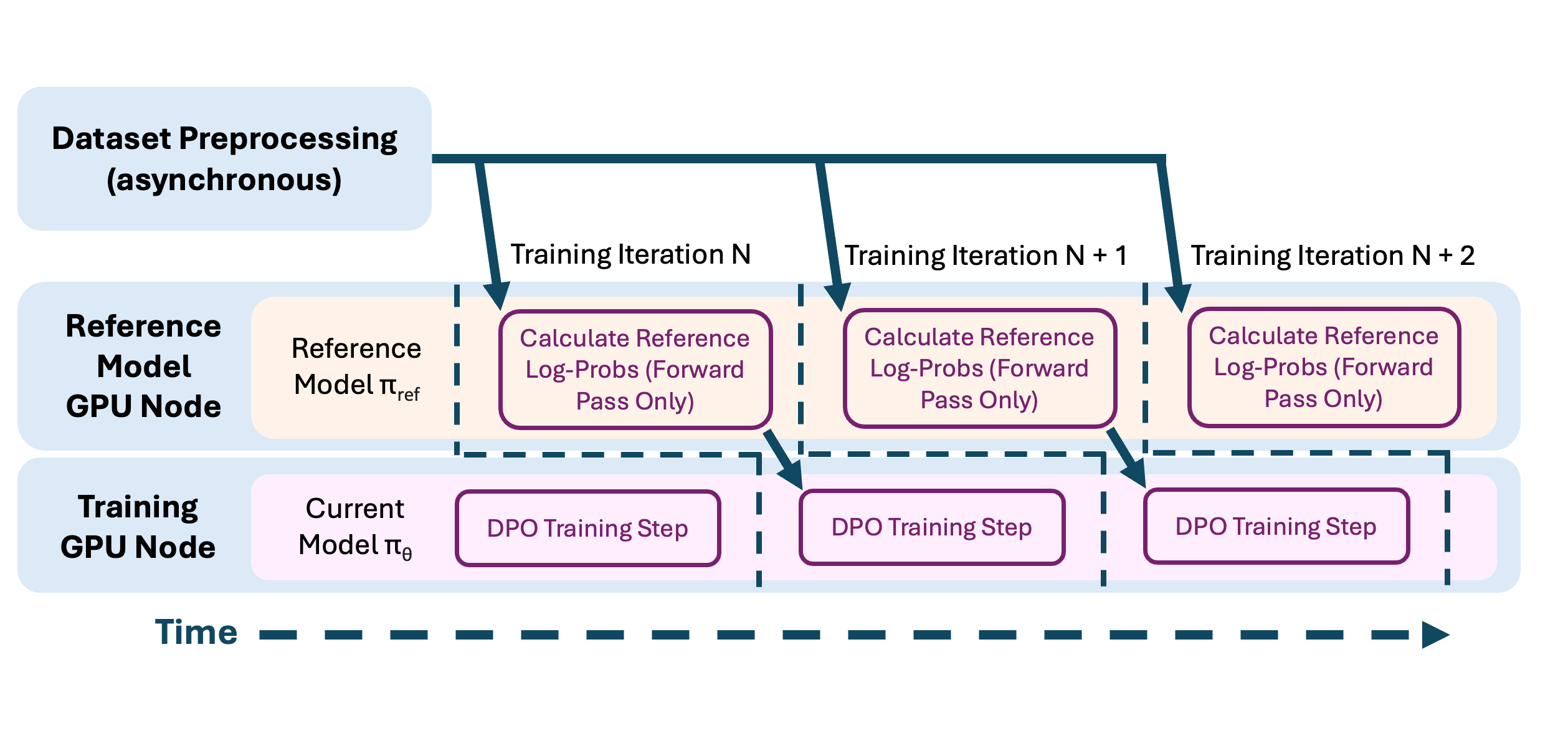
For more on preference tuning, and for complete example configs, see our end-to-end-example for DPO with synthetic data on Anyscale. Note that our current implementation requires that each reference model instance fit on one GPU. We're working on supporting a tensor parallel implementation for memory efficient inference.
With DPO, we recommend to set num_data_blocks_per_device higher than the defaults so as to not bottleneck the reference model log probability calculations. Make sure to go over our DPO end-to-end example and the full llmforge config reference for the details.