Multi-zone Compute Configs User Guide
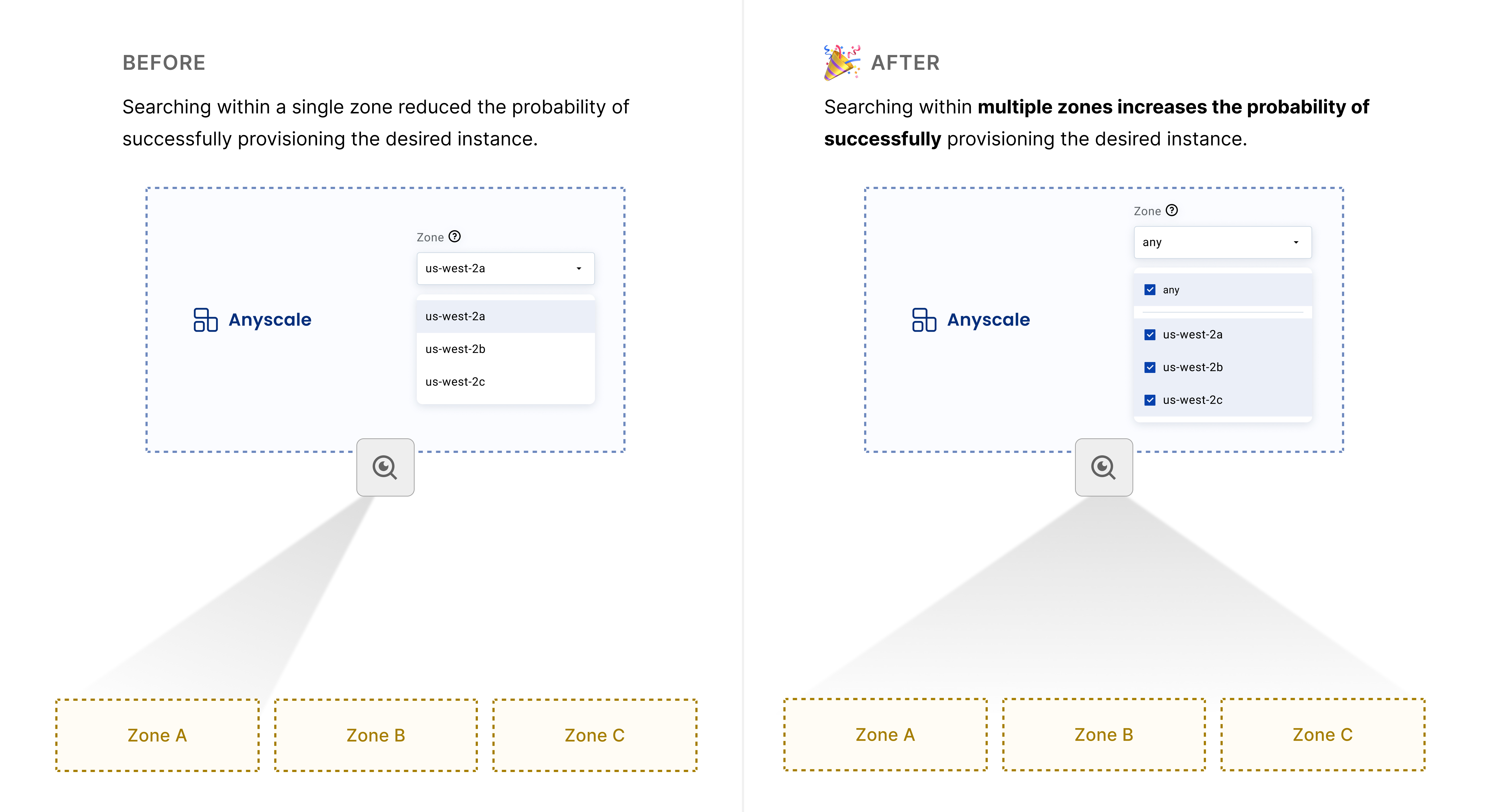
Compute capacity is often hard to find, especially for certain instance types like those with GPUs. To help with this the Anyscale platform offers several features to configure your Compute Config for multiple zones.
Once configured, Anyscale will use various internal metrics including instance type, zones requested, and other intelligence to increase the probability of success of provisioning the type of instances you want.
How to use
Via the Console
Step 1
Via the Anyscale Console in the Compute Config screen you will now see a drop down where Zones are multi-selectable as well as an additional Any option.
Simply select two or more Zones (or Any if you want Anyscale to look across the entire Region).
Step 2
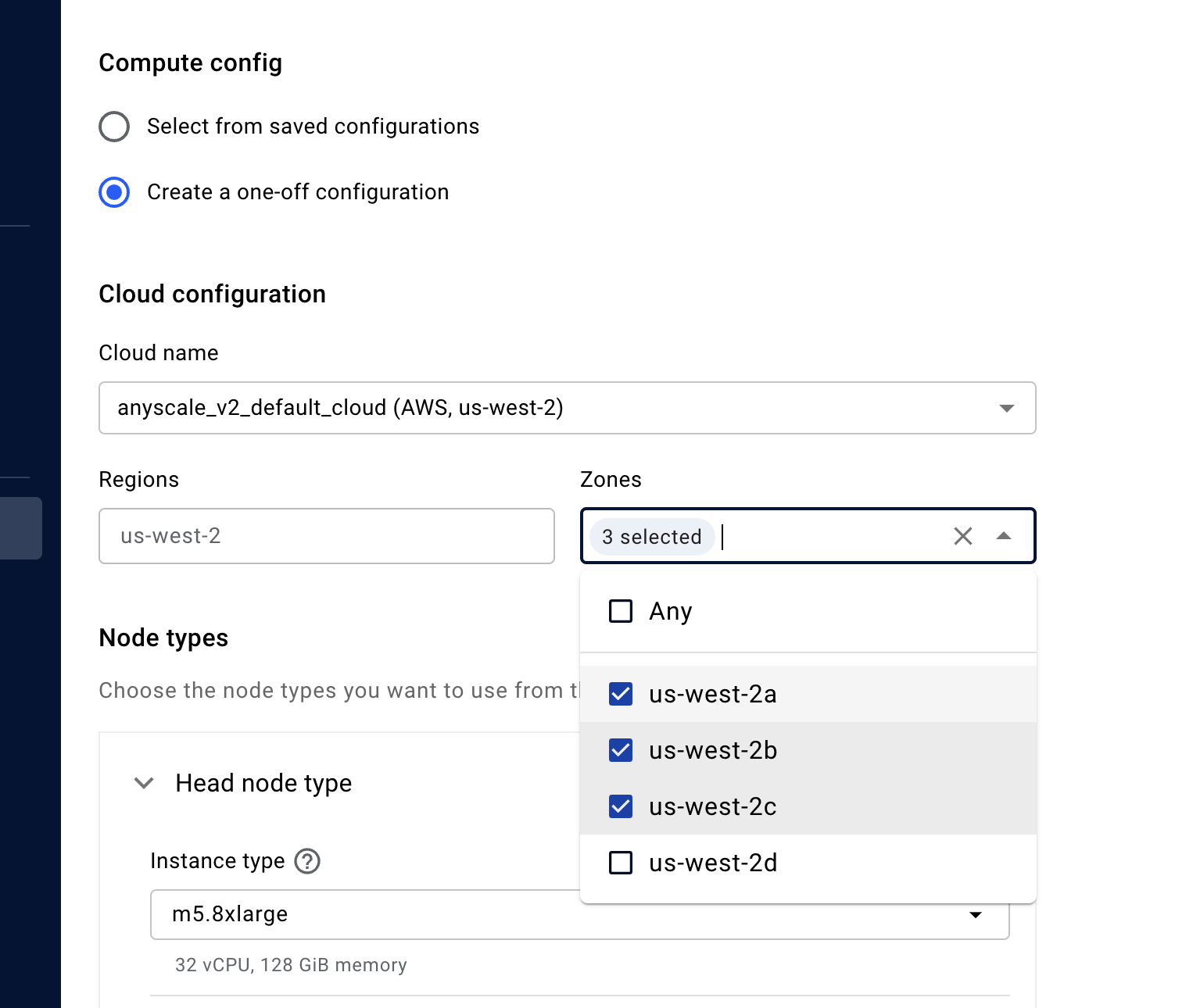
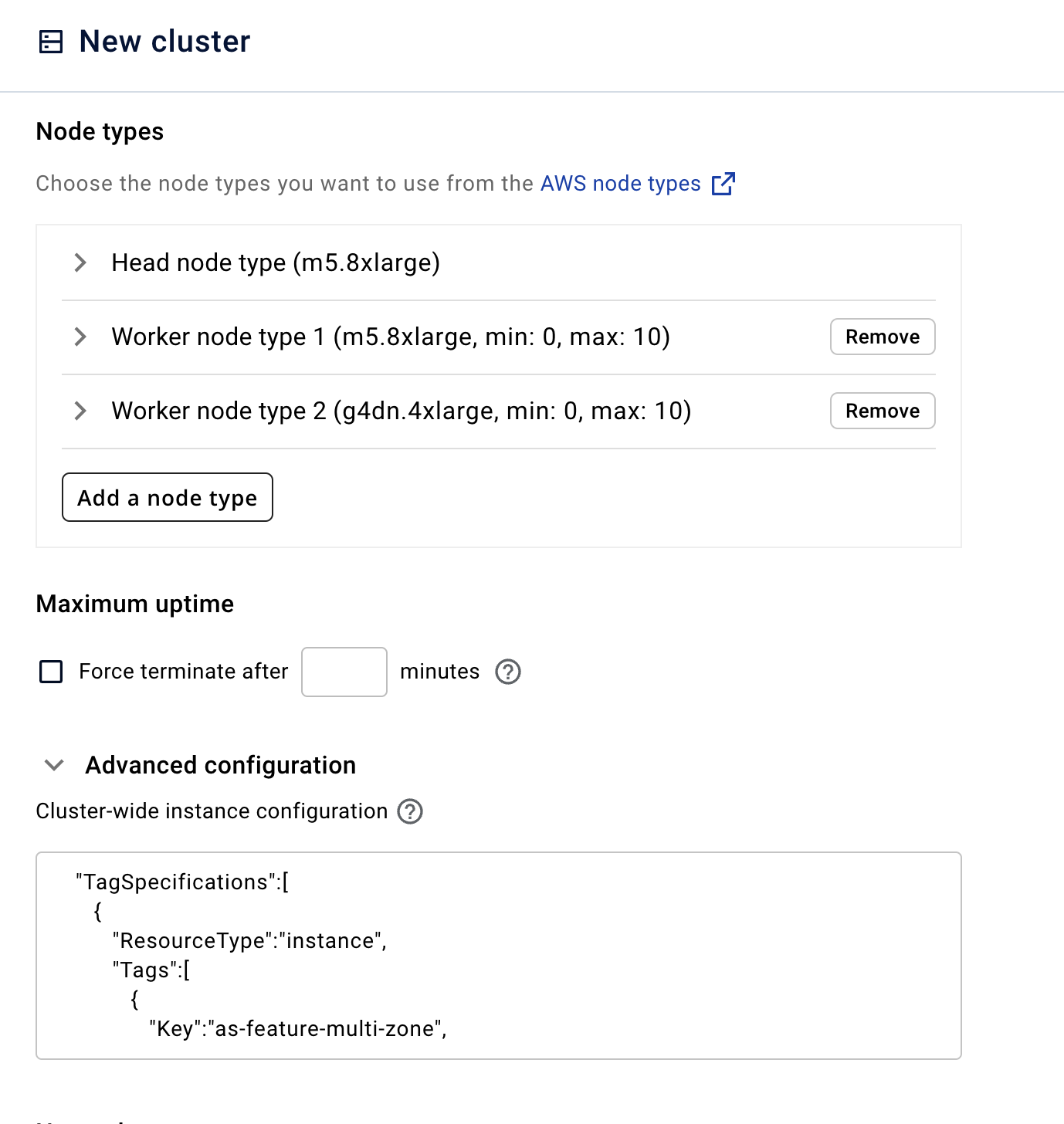
In addition to the zone configuration you will have to add the following Advanced Instance Configurations.
This can go in the cluster-wide instance configurations or you can specify it for a specific Head/Worker Node Type.
- AWS (EC2)
- GCP (GCE)
{
"TagSpecifications": [
{
"ResourceType": "instance",
"Tags": [
{
"Key": "as-feature-multi-zone",
"Value": "true"
}
]
}
]
}
{
"instance_properties": {
"labels": {
"as-feature-multi-zone": "true"
}
}
}
What it looks like in the Console. As aforementioned you can configure it to be at the Cluster-wide level…
…or for a specific Head/Worker Node Type
CLI/SDK
cloud: anyscale_v2_default_cloud_vpn_us_east_2 # You may specify `cloud_id` instead
allowed_azs:
- us-east-2a
- us-east-2b
head_node_type:
name: head_node_type
instance_type: m5.2xlarge
worker_node_types:
- name: cpu_worker
instance_type: m5.4xlarge
min_workers: 2
max_workers: 10
use_spot: true
- name: gpu_worker
instance_type: g4dn.4xlarge
min_workers: 0
max_workers: 10
aws:
TagSpecifications:
- ResourceType: instance
Tags:
- Key: as-feature-multi-zone
Value: "true"
Python SDK code
import yaml
from anyscale.sdk.anyscale_client.models import CreateClusterCompute
from anyscale import AnyscaleSDK
sdk = AnyscaleSDK()
with open('compute_config.yaml') as f:
compute_configs = yaml.safe_load(f)
# If your config file contains `cloud`, use this to get the `cloud_id`
if "cloud" in compute_configs:
compute_configs["cloud_id"] = sdk.search_clouds(
{"name": {"equals": compute_configs["cloud"]}}
).results[0].id
del compute_configs["cloud"]
config=sdk.create_cluster_compute(CreateClusterCompute(
name="my-cluster-compute",
config=compute_configs
))
As you already create a compute configuration with the JSON block via console, you can use that compute config in your Anyscale cluster, job or service YAML: such as “compute_config: multi-az”.
If you are using Anyscale SDK, you can either use cluster_compute_id with your compute configuration id, or use cluster_compute_config as a dict based on ClusterComputeConfig
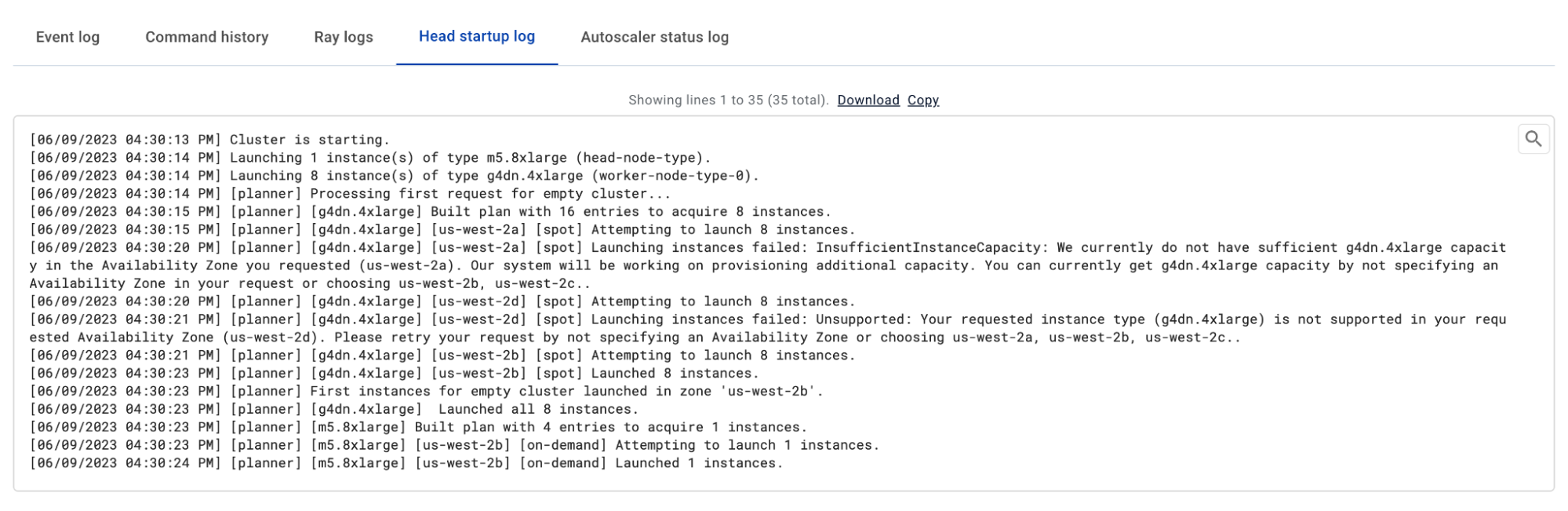
Logs
This is what it looks like:
FAQ
Question: How does it work?
At a high level, the Anyscale platform examines all variables in the Compute Config and uses them to make the right sequence of provisioning requests to the underlying Cloud Service Provider. These variables include, but are not limited to:
- Desired Instance Type for your Head/Worker Nodes.
- On-demand, Spot, or Spot with Fallback to On-demand.
- Regional/Zonal Instance Type availability.
For example, GPUs are typically more difficult to acquire than pure CPU machines, the Anyscale platform tunes the above variables to seek GPU-based machines first. Then, depending on the success of provisioning and the zones configured, the Anyscale platform will launch easier-to-acquire Instance Types in the same Zone.
The exact algorithm is constantly evolving and may be different for every customer/use-case at any point in time.
If you require and/or are interested in an in-depth answer please reach out to your Anyscale account team to coordinate a deeper conversation with Anyscale Engineering.
Question: For Clusters powering Services does it take into account dimensions such as Replicas and traffic?
It does not. Currently, application level resource utilization is considered as part of zone selection. The pattern of Any/Multizone configurations for Anyscale Services is different than batch inference, training, or fine-tuning Jobs.
Question: What happens if I specify Any but with Multi-zone turned “off”?
Any controls which Zones Anyscale will search for capacity in during initial Cluster startup. Multi-zone controls how “sticky” your Cluster is to the initial Zone that the Cluster starts in (where the Head node is in).
With Multi-zone turned off, Anyscale will only look in the Zone that your Head Node starts in and all subsequent capacity will be kept to the same Zone.
With Multi-zone on, the Anyscale platform has the ability to deploy Worker nodes in the best zone with sufficient capacity.