Run LLM batch inference on Anyscale
Run LLM batch inference on Anyscale
This page explains how to run LLM batch inference workloads on Anyscale for enhanced performance, reliability, and developer experience.
Quickstart with agent skills
The /anyscale-workload-ray-data agent skill guides you through designing and running LLM batch inference pipelines with Ray Data LLM and vLLM. Prompt it from your coding agent:
/anyscale-workload-ray-data run batch inference with Qwen2.5-7B-Instruct using the PDF data, summarize each page using the LLM
To install Anyscale agent skills, see Install Anyscale agent skills. For more example prompts, see the Batch inference skill.
Why Anyscale
LLM batch inference is the process of running an LLM over a fixed set of inputs, such as summarizing a large batch of articles or extracting structured data from thousands of documents. While powerful, it presents unique challenges in production, including variable workloads, complex CPU/GPU pipeline management, and scaling data processing. See Understand LLM batch inference basics to learn about common use cases, challenges, and how batch differs from online inference.
The ray.data.llm module makes it easy to combine distributed data processing with integrated inference engines such as vLLM. Built on Ray, it natively maximizes CPU and GPU utilization, adds fault tolerance through checkpointing, and supports flexible data connections.
Running the same workload on Anyscale takes performance and developer experience to the next level through enhanced tooling, optimizations, and production-grade infrastructure.
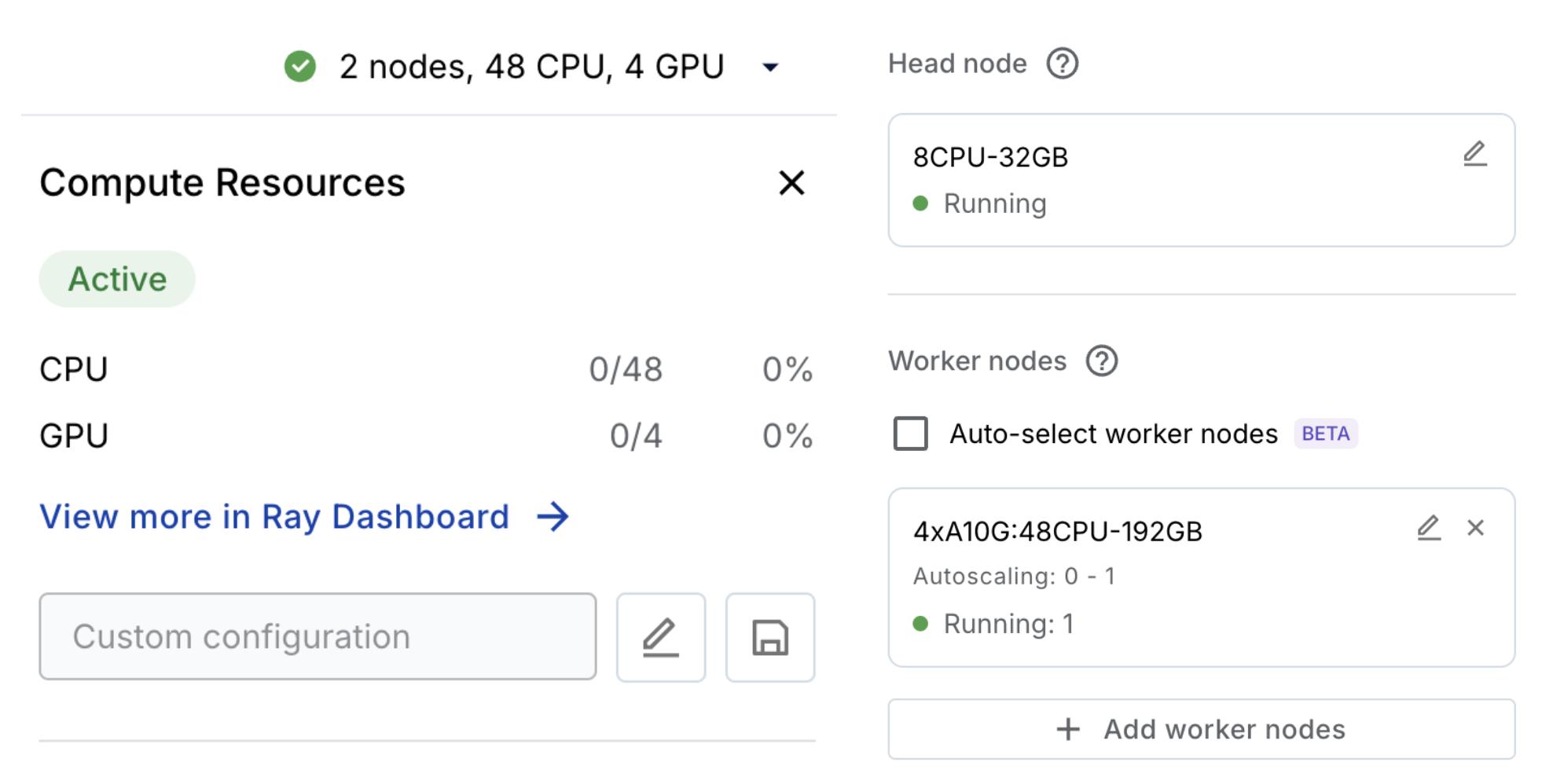
Develop with Workspaces
Anyscale's developer experience centers on making it simple to develop and debug on arbitrarily large clusters without worrying about infrastructure setup, IDE configuration, or autoscaling.
Anyscale Workspaces enable seamless development without infrastructure concerns—just like working on a laptop. See Workspaces. Workspaces provide these key advantages over local Ray cluster setup:
- Development tools: Spin up a remote session from your local IDE (Cursor, VS Code, and more) and start coding, using the same tools you love but with the power of Anyscale's compute.
- Dependencies: Install dependencies using familiar tools such as pip or uv. Anyscale propagates all dependencies to the cluster's worker nodes.
- Compute: Leverage reserved or spot instances from any compute provider by deploying Anyscale into your account. Alternatively, use Anyscale Cloud for a fully serverless experience. Under the hood, clusters automatically spin up and are efficiently managed by Anyscale.
- Debugging: Leverage a distributed debugger to get the same VS Code-like debugging experience. See Distributed debugger.
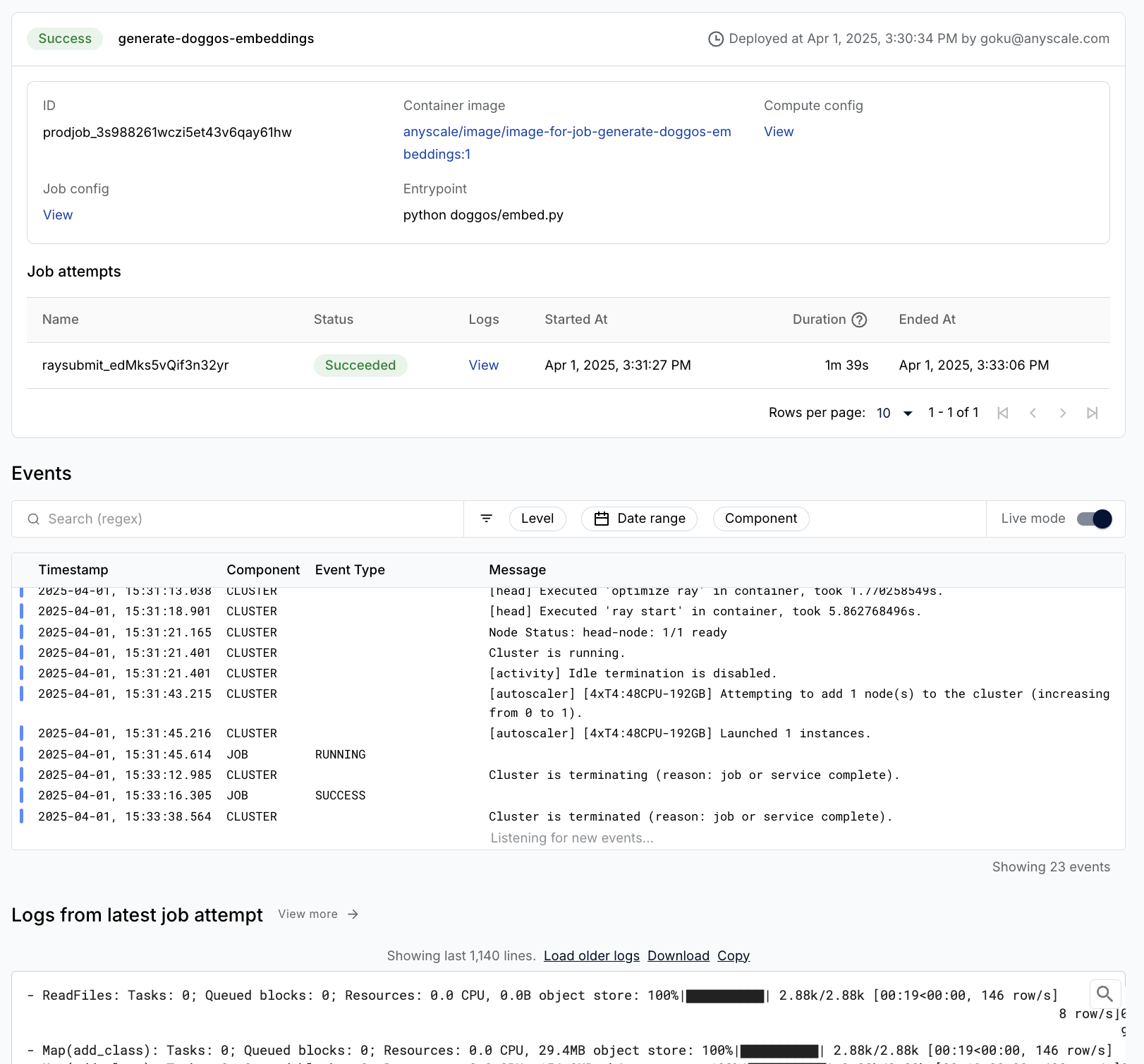
Deploy to production
For production LLM batch inference workloads, Anyscale jobs enable you to execute discrete workloads such as batch inference, embedding generation, or model fine-tuning. See What are Anyscale jobs?. Jobs provide:
- Definition and management through CLI, Python SDK, or YAML configuration. See Create and manage jobs.
- Queues and schedules for workflow orchestration. See Submit jobs to persistent job queues and Job schedules.
- Built-in observability, alerting, and monitoring. See Monitor a job.
Example Job Configuration:
# job.yaml
name: llm-batch-inference
image_uri: anyscale/ray:2.55.1-py312-cu128
compute_config:
...
entrypoint: python main.py
max_retries: 0
# Submit the job
anyscale job submit -f job.yaml
Anyscale Runtime optimizations
Ray workloads running on Anyscale automatically leverage the Anyscale Runtime, Anyscale's optimized Ray engine that delivers superior performance, scale, reliability, and efficiency for AI workloads. RayTurbo Data improvements provide up to 5x faster Parquet schema inference compared to open-source Ray Data.
For LLM batch inference specifically, Ray Data on the Anyscale Runtime delivers:
- Accelerated metadata fetching: Improved performance when reading from large datasets for the first time.
- Optimized autoscaling: Jobs can start before waiting for the entire cluster to spin up.
- High reliability: Job-level checkpointing allows jobs to resume from the previous state after failures (driver crashes, head node failures, entire cluster failures, or unexpected exceptions). Once configured, checkpointing integrates seamlessly with standard Ray Data operations. By comparison, OSS Ray Data can only recover from worker node failures by retrying individual tasks.
See Ray Data for more information.
Monitor and debug workloads
Anyscale provides enhanced debugging and observability capabilities for Ray Data workloads. The Ray Data dashboard allows you to monitor individual operators and key components of your batch workload in real time. Additional views, such as the Tasks dashboard, break down individual tasks by function, error status, and other metrics.
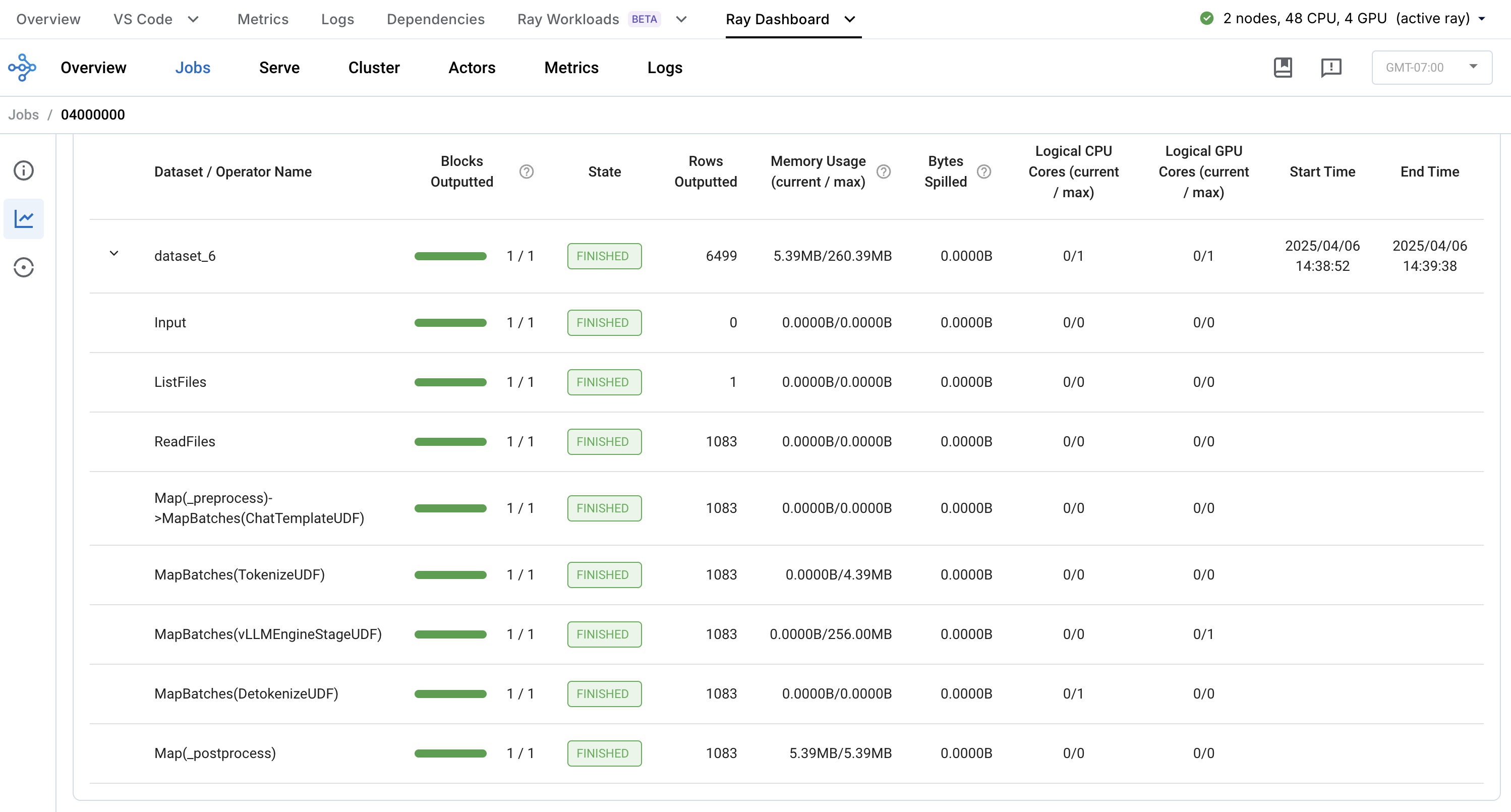
These dashboards are invaluable for debugging issues (out-of-memory errors, back pressure, scaling problems) and identifying bottlenecks to improve utilization and throughput performance.