Run batch inference with Ray Data LLM
Run batch inference with Ray Data LLM
This page shows you how to perform batch inference on large datasets using the built-in large language model (LLM) support in Ray Data. You'll learn to configure a vLLM processor and apply it to datasets for scalable text processing tasks.
Overview
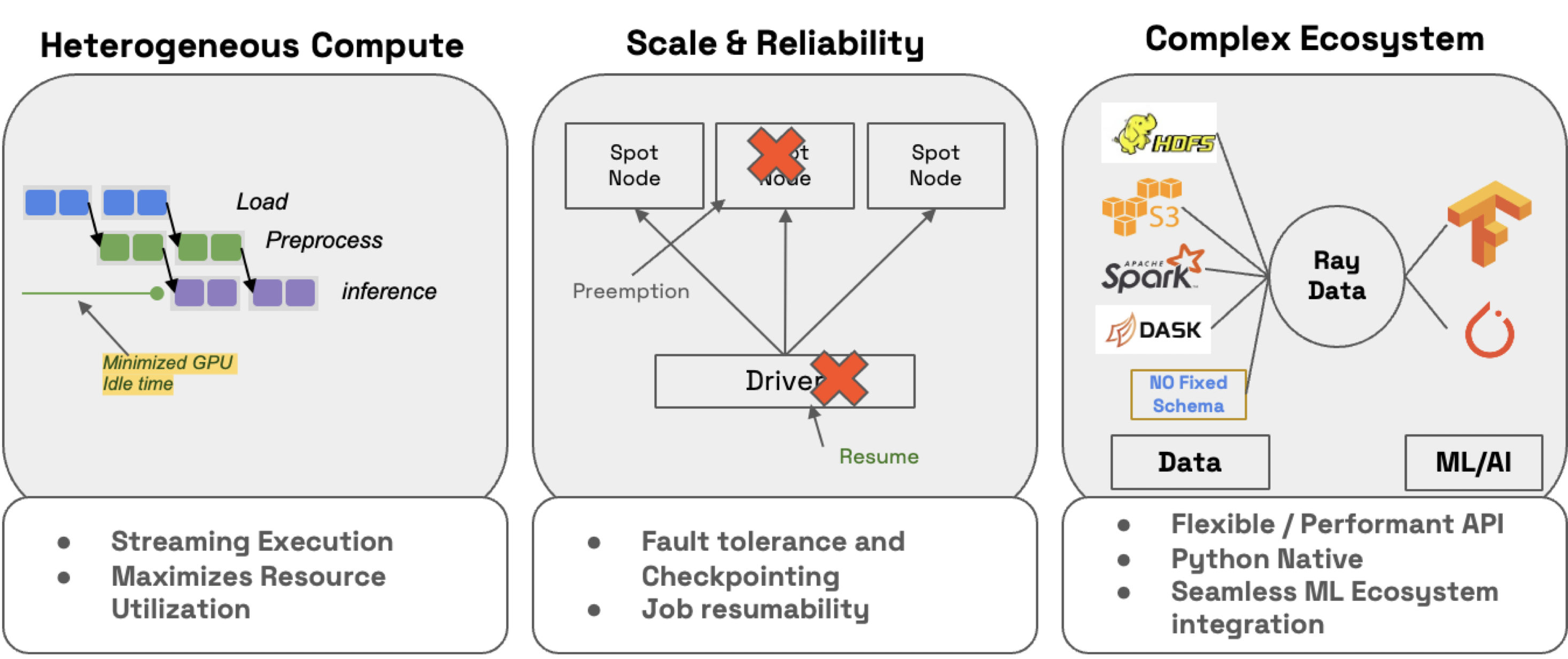
Ray Data supports LLM batch inference through the ray.data.llm module, which integrates with key LLM inference engines and deployed models. These LLM modules use Ray Data under the hood to distribute workloads and ensure they run:
- Efficiently: Minimize CPU and GPU idle time with heterogeneous resource scheduling.
- At scale: Stream execution to petabyte-scale datasets, especially when working with LLMs.
- Reliably: Checkpoint processes, especially when running workloads on spot instances with on-demand fallback.
- Flexibly: Connect to data from any source, apply transformations, and save to any format and location for your next workload.
Quick start on Anyscale
To get started quickly with batch inference on Anyscale, use the pre-built template:
- Open the text-to-text batch inference or multimodal batch inference template in the Anyscale console.
- Click Launch to deploy the example.
- Follow the template instructions to customize the deployment for your use case.
Configure the processor
First, install Ray with Data and LLM support, which also installs vLLM:
pip install -U "ray[data,llm]>=2.49.1"
Configure the vLLM engine processor to choose the model and engine settings. Models can come from the Hugging Face Hub or a local path. Anyscale supports GPTQ, GGUF, and LoRA formats.

When you apply an LLM processor, Ray Data LLM orchestrates your workload across three parallel stages: preprocessing, inference, and post-processing. Each stage can scale independently based on your resource allocation and parallelism configuration.
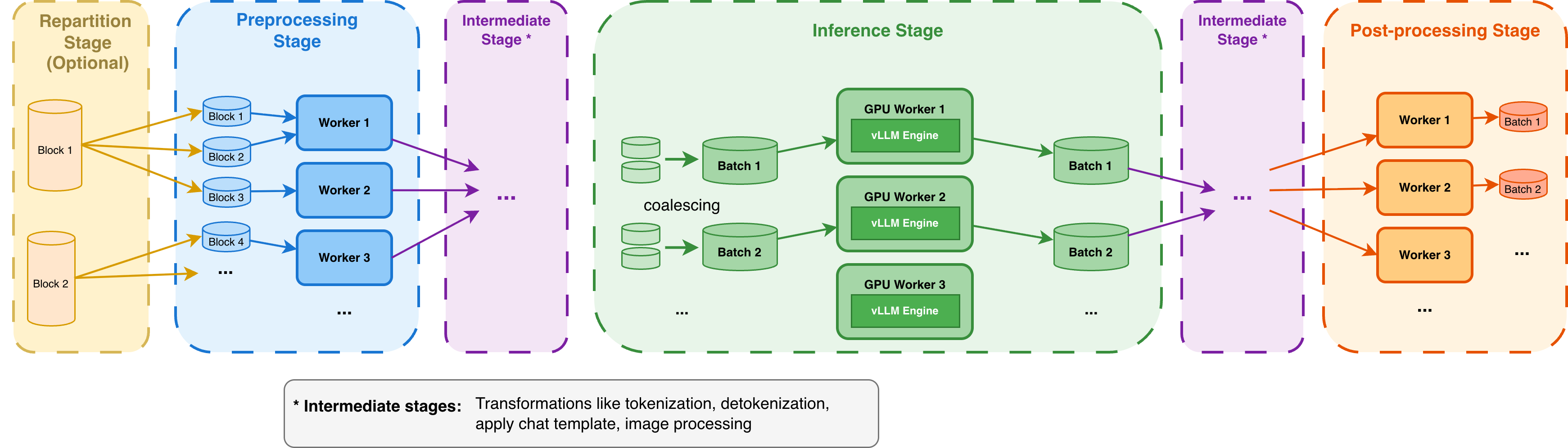
For detailed guidance on configuring parallelism for each stage and matching your resource allocation to available compute, see Configure parallelism for Ray Data LLM.
import ray
from ray.data.llm import vLLMEngineProcessorConfig
# Configure the vLLM processor
config = vLLMEngineProcessorConfig(
model_source="Qwen/Qwen2.5-7B-Instruct",
batch_size=16,
engine_kwargs={
"max_model_len": 8192
},
accelerator_type="L4",
concurrency=1, # Start with 1, increase based on available GPUs
)
You can also configure the runtime environment, request scheduling, resource requirements, tokenization, detokenization, and concurrency for data parallelism.
For the complete list of parameters and their descriptions, see the vLLMEngineProcessorConfig API.
Build the processor
To build the processor, pass the config to an LLM processor builder where you can define the preprocessing and post-processing steps around inference.
from ray.data.llm import build_processor
# Build the LLM processor
processor = build_processor(
config,
preprocess=lambda row: {
"messages": [
{
"role": "system",
"content": "Summarize the following article in 2-3 sentences, focusing on the main points."
},
{
"role": "user",
"content": row["article"]
}
],
"sampling_params": {
"max_tokens": 500,
},
},
postprocess=lambda row: {
**row, # all contents
"summary": row["generated_text"],
# add additional outputs
},
)
Run batch inference
Apply the processor to your dataset to perform batch inference. For more information on loading data with Ray Data, see Loading Data. For supported file formats, see the Input/Output reference.
# Download and load the CNN/DailyMail dataset
from datasets import load_dataset
import ray
# Load a small subset of the CNN/DailyMail dataset
dataset = load_dataset("cnn_dailymail", "3.0.0", split="test[:100]")
# Convert to Ray dataset
ds = ray.data.from_huggingface(dataset)
# Apply the processor for batch inference
results_ds = processor(ds)
results = results_ds.take_all()
# Display first few results
for i, result in enumerate(results[:3]):
print(f"Article {i+1}:")
print(f"Original extract: {result['article'][:200]}...")
print(f"Summary: {result['summary']}")
print("-" * 80)
The processor returns processed data with the original article and generated summary:
{
'article': 'NEW YORK (CNN) -- More than 80 Michael Jackson collectibles -- including the late pop star's famous rhinestone-studded glove from a 1983 performance -- were auctioned off Saturday...',
'batch_uuid': '7ca4576ae78143a88d2bae7b95b30361',
'embeddings': None,
'generated_text': 'Michael Jackson memorabilia including his iconic rhinestone glove sold at auction for hundreds of thousands of dollars...',
'generated_tokens': [785, ...],
'request_id': 0,
'time_taken_llm': 17.943071646999897,
'summary': 'Michael Jackson memorabilia including his iconic rhinestone glove sold at auction for hundreds of thousands of dollars...'
}
Advanced usage
For more advanced guides on optimized model loading, multi-LoRA, and OpenAI-compatible endpoints, see the Ray Data LLM examples and API reference.
Engine configuration
The engine_kwargs parameter provides comprehensive control over vLLM engine behavior. You can configure parameters for model parallelism settings, performance optimization, memory management, quantization, LoRA adapters, and scheduling behavior.
For the complete list of available parameters and their usage, see the vLLM engine arguments documentation.
Model parallelism
Model parallelism distributes large models across multiple GPUs when they don't fit on a single GPU. Use tensor parallelism to split model layers horizontally across multiple GPUs within a single node and use pipeline parallelism to split model layers vertically across multiple nodes, with each node processing different layers of the model.
Forward model parallelism parameters to your inference engine using the engine_kwargs argument of your vLLMEngineProcessorConfig object. If your GPUs span multiple nodes, set ray as the distributed executor backend to enable cross-node parallelism:
config = vLLMEngineProcessorConfig(
model_source="deepseek-ai/DeepSeek-R1",
accelerator_type="H100",
engine_kwargs={
"tensor_parallel_size": 8, # 8 GPUs per node
"pipeline_parallel_size": 2, # Split across 2 nodes
"distributed_executor_backend": "ray", # Required to enable cross-node parallelism
},
concurrency=1,
)
# Each worker uses: 8 GPUs × 2 nodes = 16 GPUs total
Each inference worker allocates GPUs based on tensor_parallel_size × pipeline_parallel_size.
For detailed guidance on parallelism strategies, see the vLLM parallelism and scaling documentation.
Sampling and inference configuration
The sampling_params dictionary provides fine-grained control over text generation behavior. You can configure parameters for output control, sampling behavior, penalties, biases, stopping criteria, and advanced decoding options such as structured outputs.
For the complete list of available parameters and their usage, see the vLLM SamplingParams documentation.
Troubleshoot
Missing sampling parameters
Include sampling parameters during preprocessing. Add sampling_params to your preprocess function:
processor = build_processor(
config,
preprocess=lambda row: {
"messages": [...],
"sampling_params": {
"max_tokens": 100,
"temperature": 0.5,
},
},
)
Access to gated models
For gated models such as Meta's Llama 3 family, pass your Hugging Face token through the runtime_env parameter. This sets up the runtime environment for your processor:
config = vLLMEngineProcessorConfig(
model_source="meta-llama/Meta-Llama-3-8B-Instruct",
runtime_env={
"env_vars": {
"HF_TOKEN": "your_hugging_face_token_here",
},
},
)
Get your Hugging Face token from the Hugging Face settings page. Ensure you have access to the gated model before using it.
Fix GPU OOM issues
If you encounter CUDA out of memory errors, consider the following strategies to optimize GPU memory usage:
- Reduce batch size: Start with smaller batches (8-16) and increase gradually.
- Lower
max_num_batched_tokens: Reduce from 4096 to 2048 or 1024. - Decrease
max_model_len: Use shorter context lengths when possible. - Adjust
gpu_memory_utilization: Set to 0.75-0.85 instead of the default 0.90. - Use smaller models: Consider smaller model variants for resource-constrained environments.
- Scale up infrastructure: Use a larger GPU or distribute across multiple nodes with model parallelism (tensor parallelism or pipeline parallelism).
For additional guidance on GPU selection and configuration, see Choose a GPU for LLM serving.
Monitor your workloads
Ray provides an extensive observability suite with logs and a dashboard to monitor and debug your batch inference workloads. The dashboard includes:
- Cluster resource monitoring: Track memory, CPU, and GPU utilization across your cluster nodes.
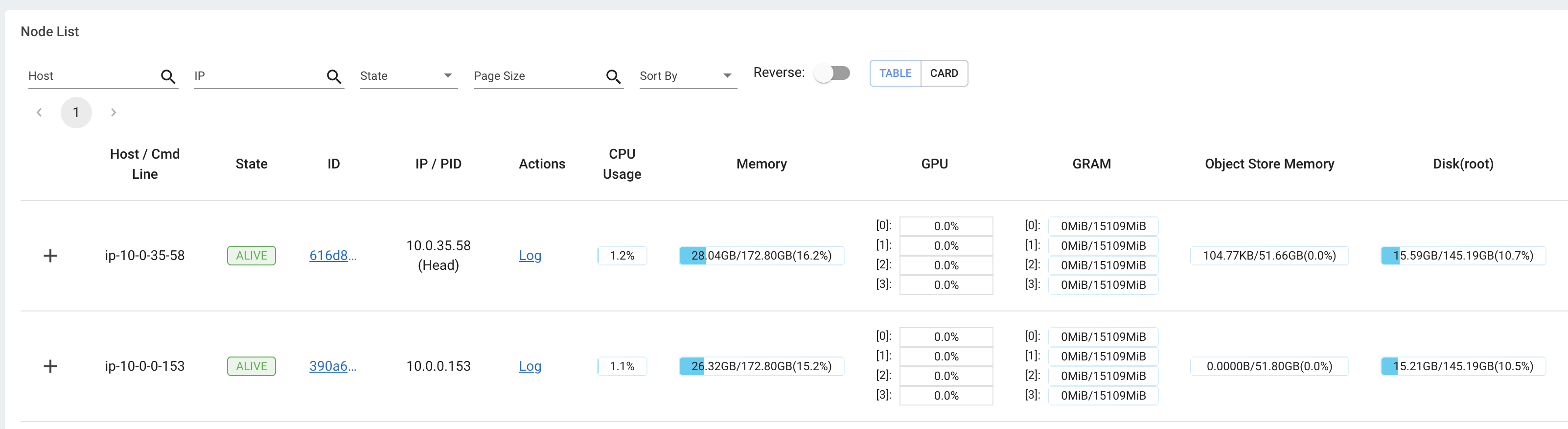
- Task execution views: Monitor running tasks, utilization across instance types, and autoscaling behavior.

This monitoring is especially valuable for LLM batch inference workloads, where you can inspect each processing stage and identify bottlenecks or optimization opportunities.
Ray Data streamlines LLM batch inference by combining distributed data processing with integrated inference engines. This makes it easy to scale from small experiments to production workloads while maximizing resource utilization, providing fault tolerance through checkpointing, and supporting flexible data connections. You can focus on model quality and application logic rather than infrastructure complexity.