Speed and memory optimizations for LLM post-training and fine-tuning
Speed and memory optimizations for LLM post-training and fine-tuning
This guide uses LlamaFactory as an example framework. Anyscale supports multiple frameworks for LLM post-training. See Choose a framework for LLM post-training.
This guide covers key techniques to accelerate your LLM post-training and reduce memory consumption using LLaMA-Factory on Anyscale. You learn about LoRA, QLoRA, DeepSpeed, and other advanced optimizations to make your training runs faster and more efficient.
LoRA
LoRA keeps the pretrained weights frozen and trains small low-rank adapters alongside them. Because you only update a tiny set of parameters, LoRA cuts VRAM and speeds up training compared to full fine-tuning.
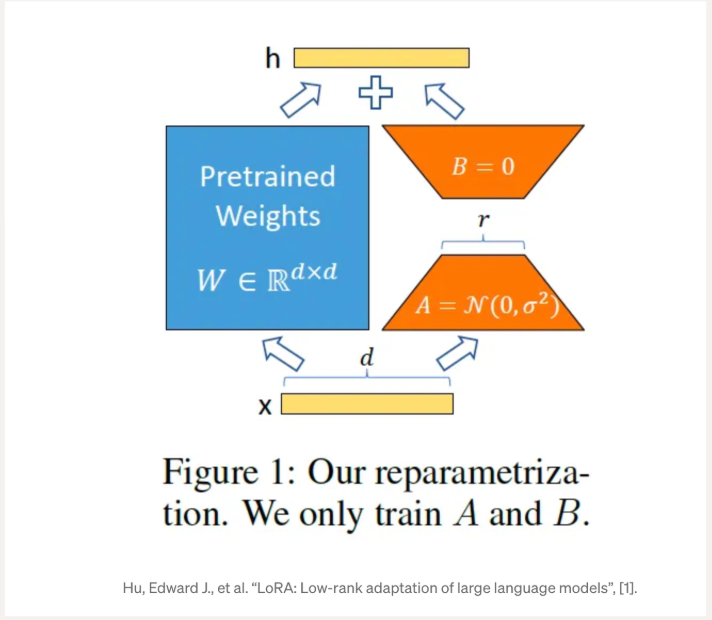
The following are key parameters for setting up LoRA:
- lora_rank: Sets the adapter rank (reduction dimension). Higher ranks can improve quality (with diminishing returns) and increase VRAM and compute.
- lora_target: Specifies which modules get adapters. Using
allmaximizes coverage, while a subset (for example,q_proj,v_proj,o_proj,gate_up_proj) reduces memory usage.
See the documentation for your model for recommended ranks and targets for best results.
At inference, you can either serve the LLM with adapters or merge the adapters into the base weights for faster inference. See Deploy multi-LoRA adapters on LLMs and Merge LoRA adapters.
# qwen_lora_sft.yaml
### method
finetuning_type: lora
lora_rank: 8 # Higher rank means more trainable parameters and memory usage.
lora_target: all
QLoRA
QLoRA begins by quantizing the large base model to a lower precision—typically 4-bit or 8-bit—and then freezing its weights. While 8-bit quantization offers less memory savings, it preserves more precision, leading to more stable training that's closer to a full-precision run. For even more efficiency, you can enable double_quantization to further compress the model's metadata.
With the base model frozen, training focuses exclusively on updating only the small LoRA adapter parameters. During the forward and backward passes, the framework dequantizes the necessary weight blocks from the quantized model just-in-time into a higher-precision compute type (such as BF16 or FP16). The system uses these full-precision weights for the calculation and then immediately discards them, keeping memory usage consistently low throughout the process.
You can use QLoRA-style training in two ways:
Approach 1: On-the-fly quantization
This is the simplest and most common method. You load the LLM in its original precision (for example, BF16), and a quantization backend (such as bitsandbytes, HQQ, EETQ) intercepts the weight tensors and stores the base weights in low precision (4-bit or 8-bit) in memory while keeping them frozen.
- Use 4-bit for maximum VRAM savings.
- Use 8-bit for a more conservative and potentially more stable option.
# qwen_qlora_sft.yaml
### model
model_name_or_path: Qwen/Qwen2.5-7B-Instruct # Path to a full-precision model for on-the-fly quantization.
quantization_bit: 4 # Use 4-bit quantization (or 8).
quantization_method: bnb # Use bnb for BitsAndBytes (QLoRA), or others such as hqq/eetq.
double_quantization: true # Usually paired with bnb. Uses a second quantization pass to reduce the memory footprint of quantization constants themselves. Disable only if you encounter issues.
### method
finetuning_type: lora # Must be paired with LoRA.
lora_target: all # Apply LoRA adapters to all possible layers.
Approach 2: Load a quantized model and train LoRA adapters
This method involves loading a model that has already been quantized and saved to disk (for example, in GPTQ or AWQ format) and then training a LoRA adapter on top of it.
# qwen_ptq_lora_sft.yaml
### model
model_name_or_path: Qwen/Qwen2.5-7B-Instruct-AWQ # Example PTQ model repo or local path.
### method
finetuning_type: lora
lora_target: all
Don't set quantization_bit, quantization_method, or double_quantization when loading an already quantized model.
DeepSpeed integration
DeepSpeed is a library from Microsoft that optimizes large-scale training. Its flagship feature is ZeRO (Zero Redundancy Optimizer), which partitions the model's training state (optimizer states, gradients, and parameters) across multiple GPUs. This is especially useful for large-model or full-parameter post-tuning.
How DeepSpeed ZeRO works
Higher ZeRO stages save more GPU VRAM but can slow down training due to increased communication between GPUs.
- ZeRO Stage 1: Partitions the optimizer states.
- ZeRO Stage 2: Partitions optimizer states and gradients.
- ZeRO Stage 3: Partitions optimizer states, gradients, and the model parameters.
For even greater memory savings, you can combine ZeRO Stage 2 and 3 with CPU offload, which moves the partitioned states out of GPU VRAM and into CPU RAM. While this allows you to train massive models on limited hardware, it increases I/O and significantly slows down training.
With LoRA, only a small subset of model parameters is trainable, so the total optimizer state size is much smaller than in full fine-tuning. Offloading them to the CPU usually adds interconnect latency without freeing up a meaningful amount of GPU memory, so it's generally best avoided.
DeepSpeed with quantization
Combining DeepSpeed and quantization has limitations, and compatibility depends on the specific quantization method and the DeepSpeed ZeRO stage you use. The following are key points and tested examples to consider:
- ZeRO Stage 3 is generally not compatible with quantization. This includes both on-the-fly quantization (
bnb) and loading pre-quantized models. - When using ZeRO Stage 1 or 2 with a pre-quantized model, you must ensure the training precision matches what the model supports. For example, AWQ models support
fp16training only, so you must setfp16: truein your configuration file.
Configuration
To enable DeepSpeed in LLaMA-Factory, specify a path to a DeepSpeed JSON configuration file in your main training YAML.
# llama_full_sft_deepspeed.yaml
### Training
deepspeed: /mnt/cluster_storage/ds_z3_config.json # Path to your DeepSpeed JSON config. Make sure the path is accessible to all worker nodes.
### Method
finetuning_type: full # Or lora with lora_rank and lora_target.
### Ray
ray_num_workers: 8 # Shards the optimizer states, gradients, and model parameters on 8 GPUs.
Example DeepSpeed configurations
The following are sample configurations for all three stages:
ZeRO-1 and 2
This is a great starting point for multi-GPU training and enables larger models and batches on smaller GPUs with minimal performance overhead.
To use ZeRO-2 instead of ZeRO-1, change the stage value to 2. To disable CPU offloading, remove the offload_optimizer section entirely.
ds_z1_config.json
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 1,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": false,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true,
"round_robin_gradients": true
}
}
ZeRO-3
ZeRO-3 introduces additional configuration fields for parameter partitioning, prefetch and communication, and optional offload. Use this when you need to fit extremely large models and can accept slower training.
To disable CPU offloading, remove both the offload_optimizer and offload_param sections entirely.
ds_z3_config.json
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": false,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
For more DeepSpeed configurations with LLaMA-Factory, see the LLaMA-Factory repo. For the DeepSpeed configuration reference, see the DeepSpeed documentation.
Other optimizations
Flash Attention
Flash Attention is a highly optimized attention kernel that avoids writing the large intermediate attention matrix to GPU memory. This speeds up training and inference while reducing memory usage, especially for long contexts. Many stacks enable it automatically.
flash_attn defaults to auto. Set flash_attn: fa2 to enable Flash Attention 2. Flash Attention 2 isn't supported on Turing GPUs (for example, T4).
Fused kernels
Fused kernels are techniques that combine multiple separate GPU operations (for example, a matrix multiplication followed by an activation function) into a single operation. This reduces the overhead of launching multiple kernels and minimizes data movement between GPU memory levels, leading to faster execution.
To enable fused kernels during post-training, use the following configuration:
# qwen2.5_lora_sft.yaml
### Acceleration methods
# Both methods can be enabled at the same time.
flash_attn: fa2
enable_liger_kernel: true
You can use FlashAttention and Liger fused kernels together, but actual speed and memory gains vary with GPU architecture, sequence length, batch size, precision, kernel availability, and runtime choices (for example, ZeRO stage, gradient checkpointing). Benchmark your training workloads to confirm improvements.
Post-training quantization (PTQ)
Post-training quantization (PTQ) is the process of quantizing a model after fine-tuning completes. You typically do this as a final step to prepare a model for deployment with a smaller memory footprint and faster inference speed. However, it may lead to slight accuracy degradation.
How PTQ differs from QLoRA
While both involve quantization, they serve different purposes at different stages:
- QLoRA quantizes the base model or loads a quantized model during training to reduce VRAM usage.
- PTQ quantizes the final, trained model after training to create an efficient artifact for inference.
For more details on applying PTQ, see Post-training quantization (PTQ).
Note on HF Accelerate
LLaMA-Factory's integration with Ray already handles distributed training using Hugging Face (HF) Accelerate with Ray Train, giving you the recommended setup out of the box.
For this reason, don't use the accelerate launch command manually. SSHing into nodes to run this command bypasses Anyscale's orchestration layer, which means you lose critical features such as autoscaling, observability, and fault tolerance. Provide your Ray configuration, and the framework correctly manages execution for you.