Why post-train your LLM
Why post-train your LLM
While pre-trained models are powerful generalists, post-training is the key to unlocking their true potential for your specific needs. This process transforms a general-purpose tool into a specialized asset, delivering significant advantages that translate into better performance, a stronger business case, and more secure, reliable AI systems.
For an overview of the post-training methods for specializing a model, including continued pre-training, supervised fine-tuning, and reinforcement learning, see LLM post-training and agentic tuning.
Improve performance and specialization
Post-training is a strategic process that transforms a general-purpose model into a high-performance, specialized asset. By continuing the training process on your own curated data, you give the model deep, domain-specific expertise and sharpen its capabilities for the tasks that matter most to your business.
-
Specialize in a domain: With continued pre-training, you can teach the model your unique business context by training it on targeted datasets, such as legal documents, medical research, or financial reports. This process injects specialized knowledge directly into the model's parameters, teaching it technical jargon and industry-specific concepts absent from its general training. For example, a base model might give a generic summary of a contract, but a model fine-tuned on legal data can analyze specific clauses, identify risks, and reference relevant precedents with far greater accuracy.
-
Sharpen task-specific skills: Beyond broad knowledge, you can use supervised fine-tuning (SFT) to make a model excel at specific, well-defined tasks. By training it on thousands of high-quality examples (for example, an article paired with its summary), you can create an expert summarizer. This applies to a wide range of functions, including sentiment analysis, question-answering, and generating structured outputs such as JSON or HTML, often yielding more consistent and reliable results than prompt engineering alone.
-
Improve tool use and agentic behavior: You can post-train a model on successful examples of tool use or function calls, making it a more reliable "agent." This is critical for building complex, multi-step workflows where the model must autonomously interact with other software to accomplish a goal. You can also use reinforcement learning from verifiable rewards (RLVR), with algorithms such as GRPO or TAPO, to further improve multi-step autonomy and calibration.
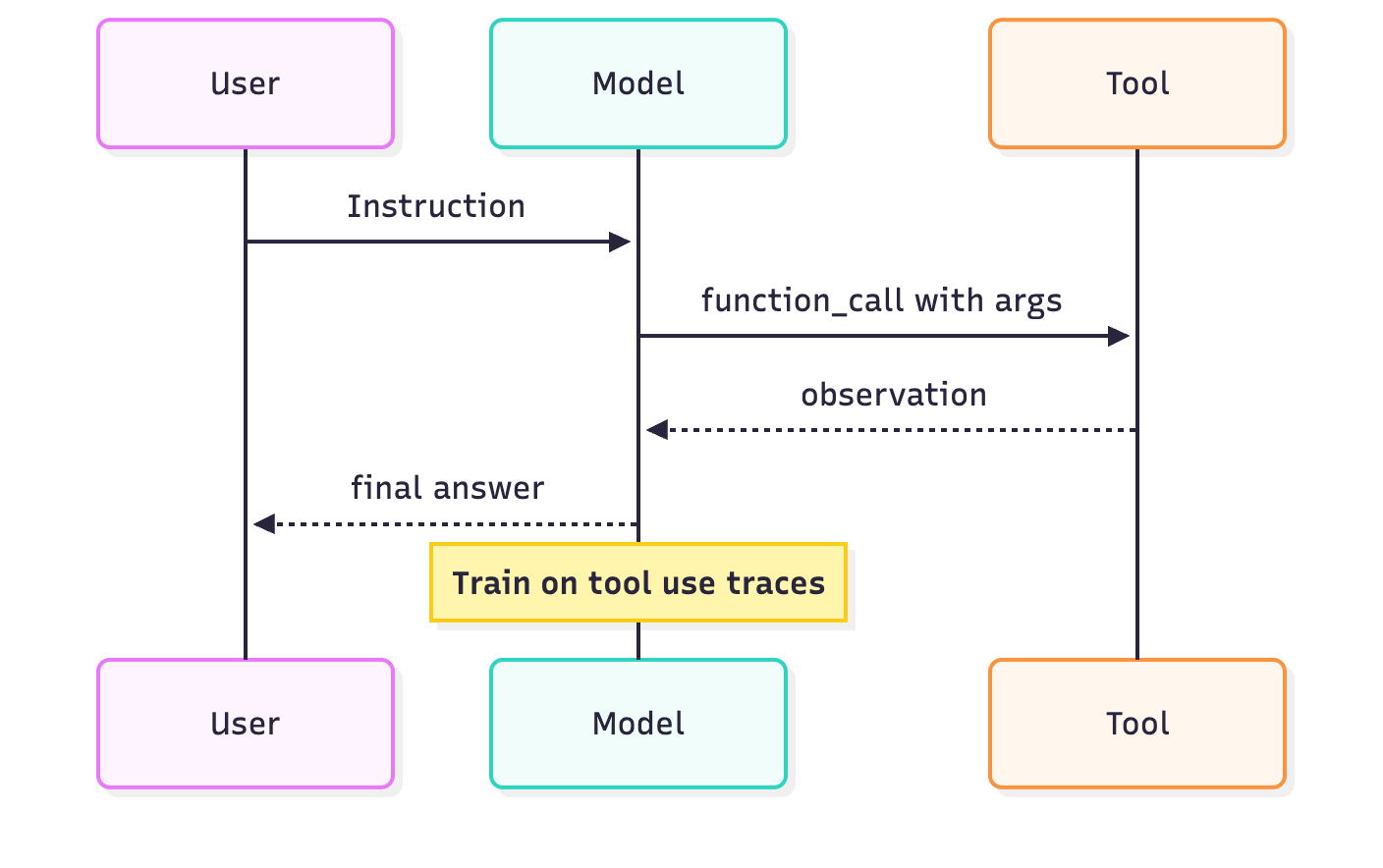
- Distill into a smaller model: Post-training lets you "distill" the knowledge from a large, powerful model into a smaller, faster, and cheaper one. This gives you state-of-the-art performance in an efficient package tailored to your needs. A specialized small model can often outperform a much larger, general-purpose one on a specific task, reducing both cost and latency.
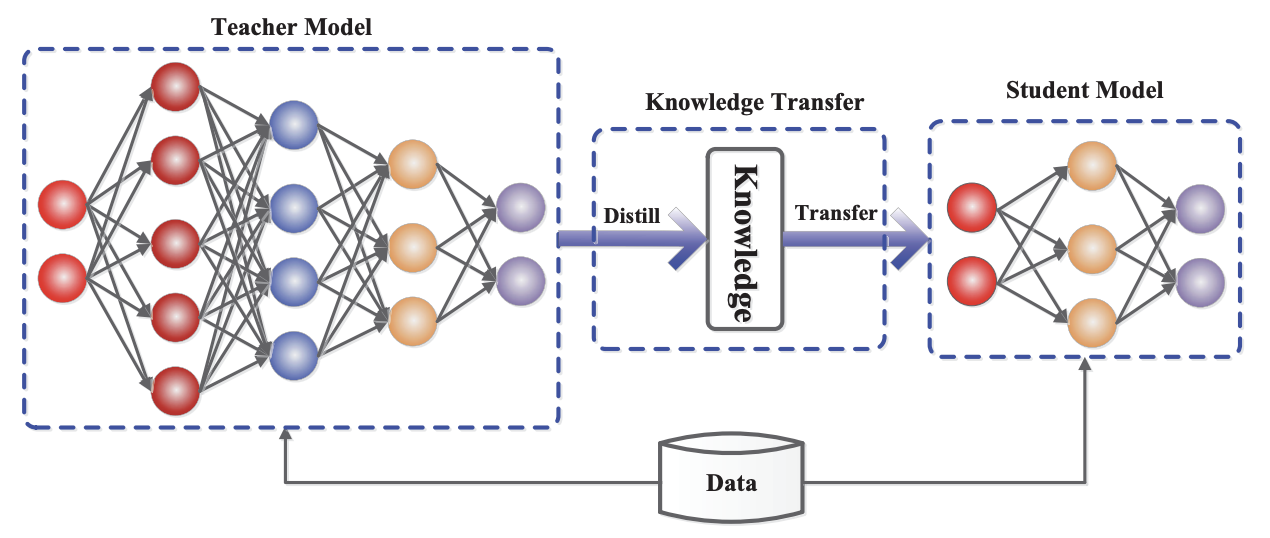
Source: Knowledge Distillation: A Survey — Gou, Yu, Maybank, & Tao (2021).
Improve business ROI and operational efficiency
Beyond raw performance, post-training creates business value by making your AI operations more efficient, scalable, and cost-effective.
-
Lower costs and latency: Specialization and distillation let you use a smaller, cheaper model that outperforms a larger, general-purpose one. This not only reduces hosting costs but also leads to lower inference latency. Furthermore, because SFT embeds instructions directly into the model's weights, you can use shorter prompts, saving significantly on input token costs.
-
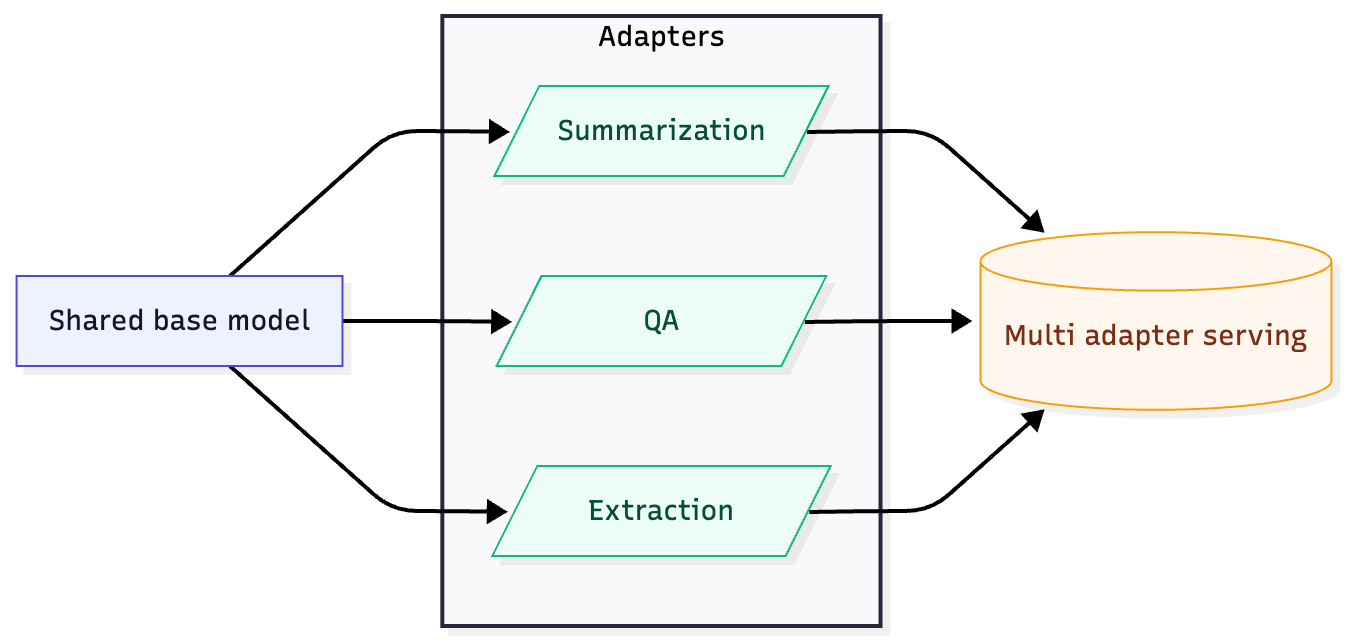
Efficiently create specialized models: Instead of training multiple full models, parameter-efficient fine-tuning (PEFT) techniques such as LoRA and QLoRA let you create lightweight "adapters" for different tasks. These methods drastically reduce the computational resources required, democratizing access to custom AI and letting you cost-effectively train many specialists on a single base model. This approach also simplifies deployment, as you can serve all your specialized adapters with one model. See Deploy multi-LoRA adapters on LLMs for more details on multi-LoRA serving.
Enhance safety, control, and data privacy
Post-training gives you direct control over your model, which is essential for ensuring safety, alignment, and security.
-
Enhance data privacy and security: For organizations in regulated industries such as finance and healthcare, data privacy is non-negotiable. When you post-train on Anyscale, training happens inside your secure environment. This lets you use proprietary and sensitive data without exposing it to external services, which mitigates security risks and helps with compliance. For details on how to prepare your data for post-training, see Dataset preparation for LLM post-training.
-
Align behavior with brand and style: Post-training is a powerful tool for controlling the stylistic aspects of a model's output. Use SFT on style or persona examples; preference-tuning methods (DPO, KTO, SimPO) can further shape outputs. The model internalizes and replicates this style, ensuring brand consistency and a more authentic user experience.
-
Improve factual consistency and reduce hallucinations: By post-training on a curated, high-quality, and factually accurate dataset, you can significantly improve a model's reliability. This narrows the model's focus to a trusted knowledge base, reducing the chance it generates plausible but incorrect information. Advanced preference-tuning techniques can explicitly train the model to prefer factually correct statements, measurably reducing its error rate.
-
Build in guardrails and control output: You can explicitly post-train the model to avoid certain topics or to not reveal sensitive internal information. This process of building in "guardrails" is more robust than simply instructing the model in a prompt because the model learns and embeds the desired behavior into its weights. This gives you more reliable control over the model's behavior, which can help prevent information leaks.
Conclusion
Post-training isn't necessarily a single step; it can be an iterative process. When new data is available, you can retrain a model to enhance its specialization and performance. These improvements in capability and safety often lead to increased user adoption. The resulting user interaction data then serves as a valuable resource for the next iteration of training, creating a self-sustaining cycle of model development.