RayLLM is deprecating soon: The Ray Team is consolidating around open source online inferencing solutions. Ray Serve LLM provides LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs. See the migration guide for transitioning your workflows.
Playground
Playground is a web-based interface that allows you to query deployed LLM services. You can use Playground to query models, view responses, and experiment with prompts and parameters. It is a great way to test how your models perform in different scenarios.
How to Use
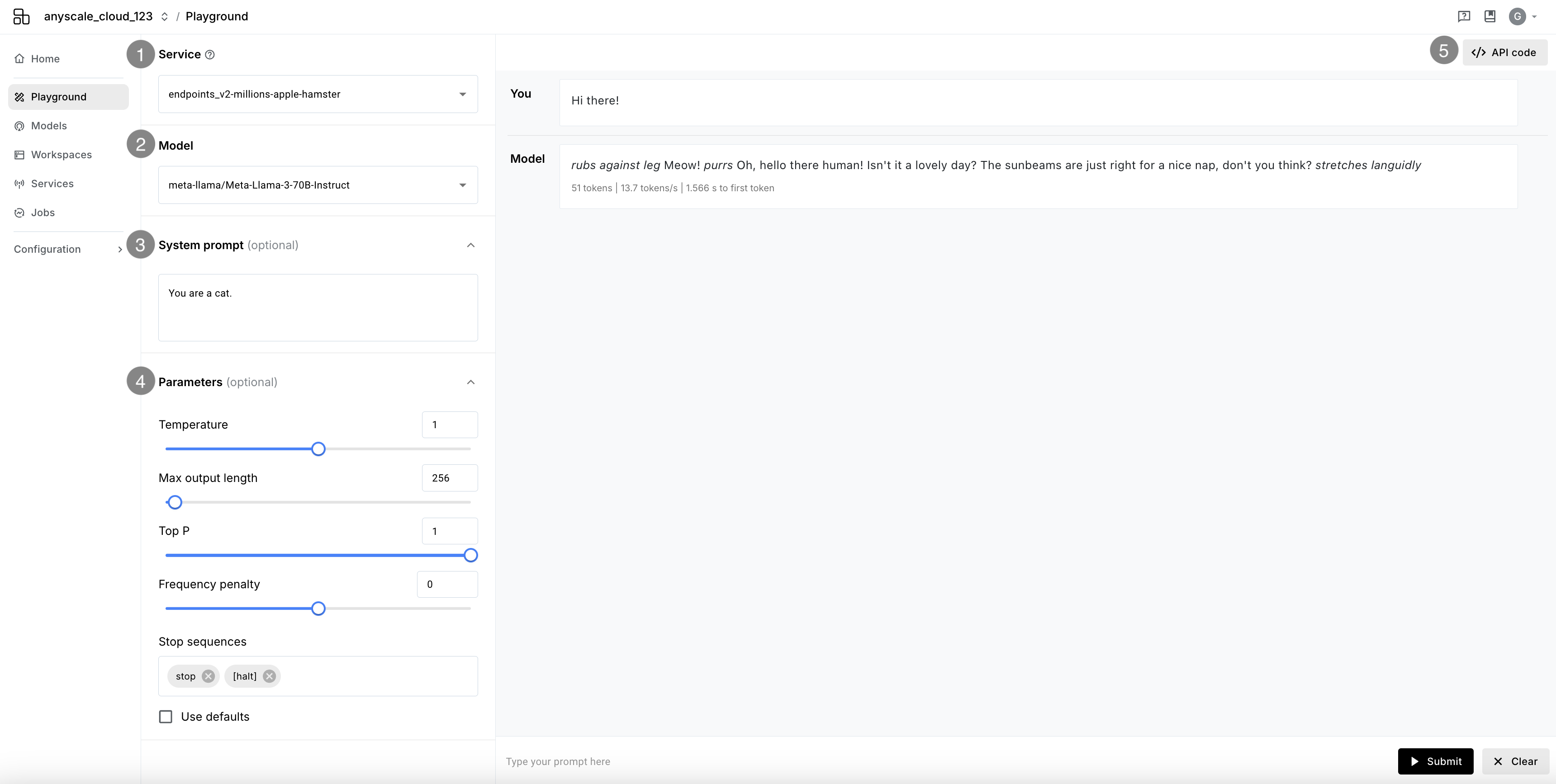
- Service: Select any a. Anyscale Service or b. Other service to query LLM responses from.
- Model: Choose a model to query on the selected service.
- System prompt: An optional prompt to provide context to the model.
- Parameters: Additional values to configure the model's behavior.
- API code: A code snippet to query the model programmatically.
Sections
Service
A Service is any service that has OpenAI-compatible APIs for Chat and Models.

Anyscale Services
Any LLM service that is deployed using a template (for example https://console.anyscale.com/v2/template-preview/endpoints_v2) and meets below requirements will appear for selection:
Runningstatus- (Token) Authentication disabled
Other
Any service that supports OpenAI's Chat and Models APIs can be added to Playground for querying.
To add a service:
- Press
+ Add - Provide the service's URL and your API key to the service
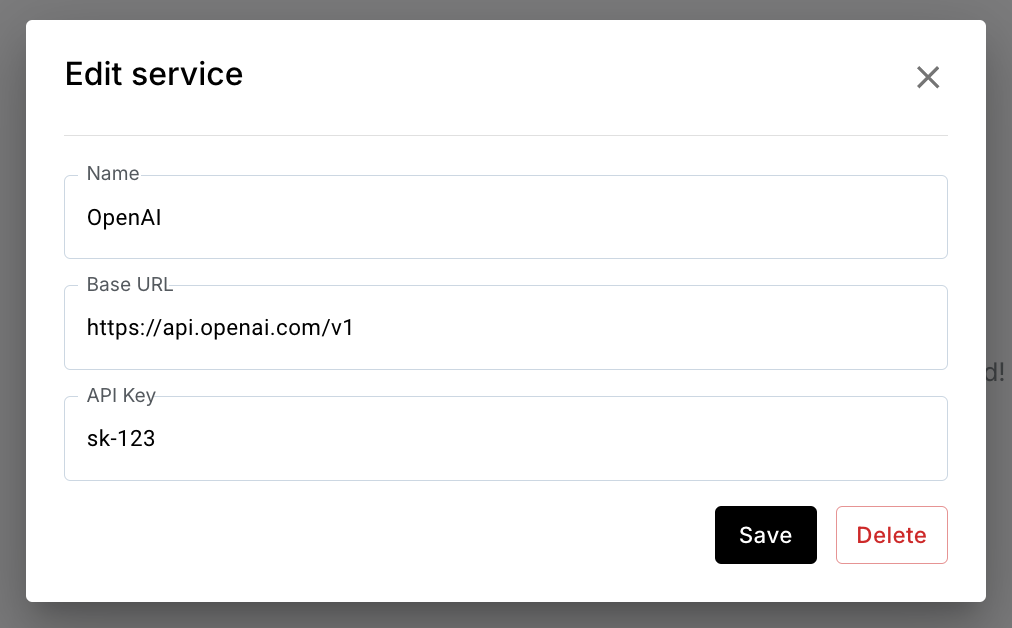
To remove a service:
-
Press the edit (
 ) icon
) icon - Press
Delete
Alternatively, you may clear cookies and site data, or log out, to remove all services.
The service's credentials are stored in your browser's storage and are not shared with Anyscale.
Parameters
Parameters are additional values that can be used to configure the model's behavior.
The following parameters are available on Playground:
To use default values, check the ☐ Use defaults box.
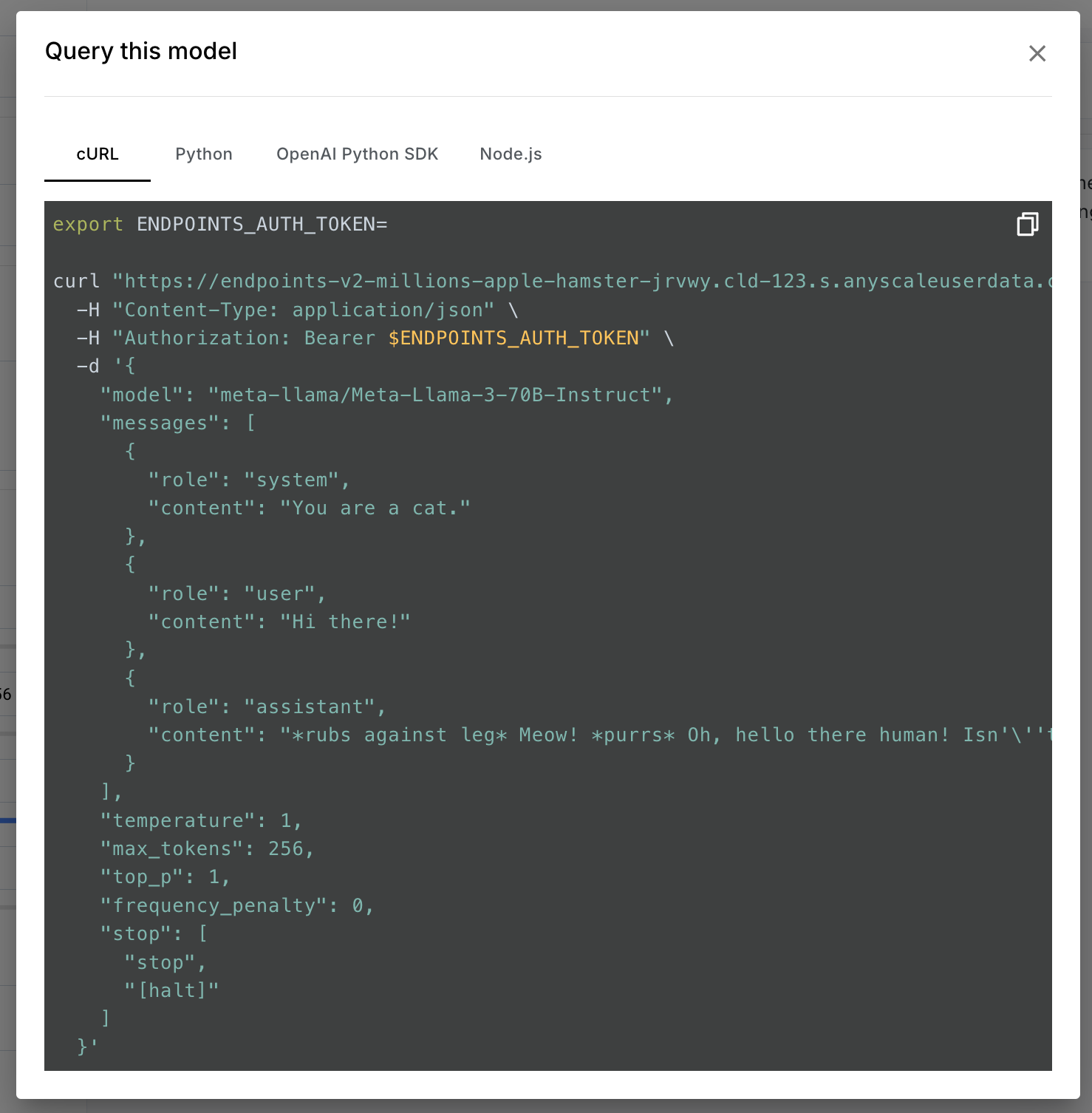
API Code
API code allows you to copy a code snippet to query the model programmatically.
The following languages/libraries are supported:
- curl
- Python
- OpenAI Python SDK
- Node.js
Other modes
These modes are for services that are Anyscale Services only.
JSON mode
JSON mode allows you to query models that were deployed with JSON mode enabled. By providing a JSON response schema along with your prompt, you will receive a JSON response from the model.
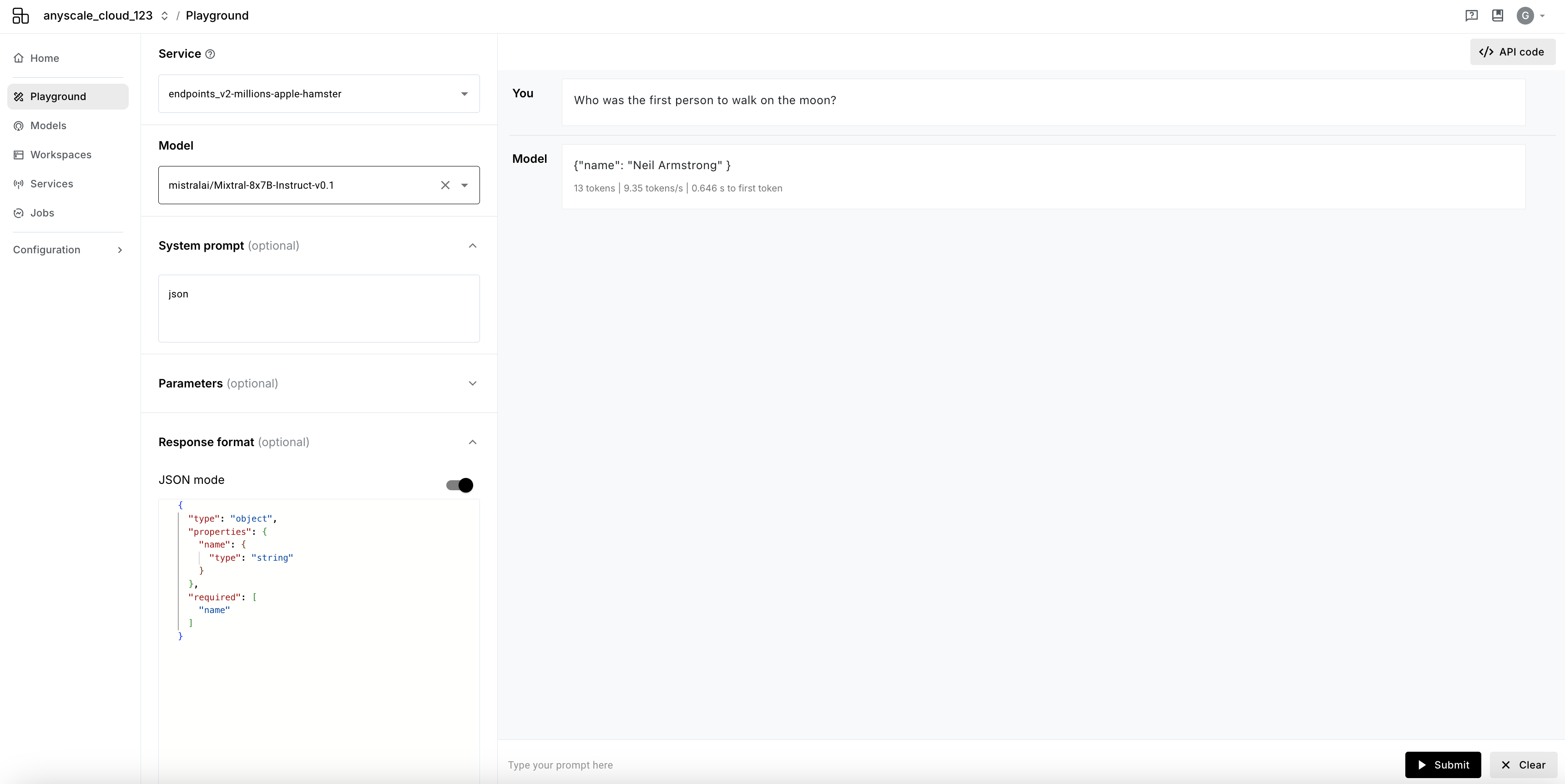
To use:
- Select a model that was deployed with JSON mode enabled
- Add the word
jsonsomewhere inSystem prompt(for exampleYou are a helpful assistant outputing in JSON) - Enable
JSON modeinResponse format - Provide a JSON response schema in the input box
Vision-language models
Vision-language models allow you to attach an image to your prompt and receive a response that is based on both the image and the prompt.
To use:
- Select a vision-language model that was deployed
-
Press the image (
 ) icon
) icon
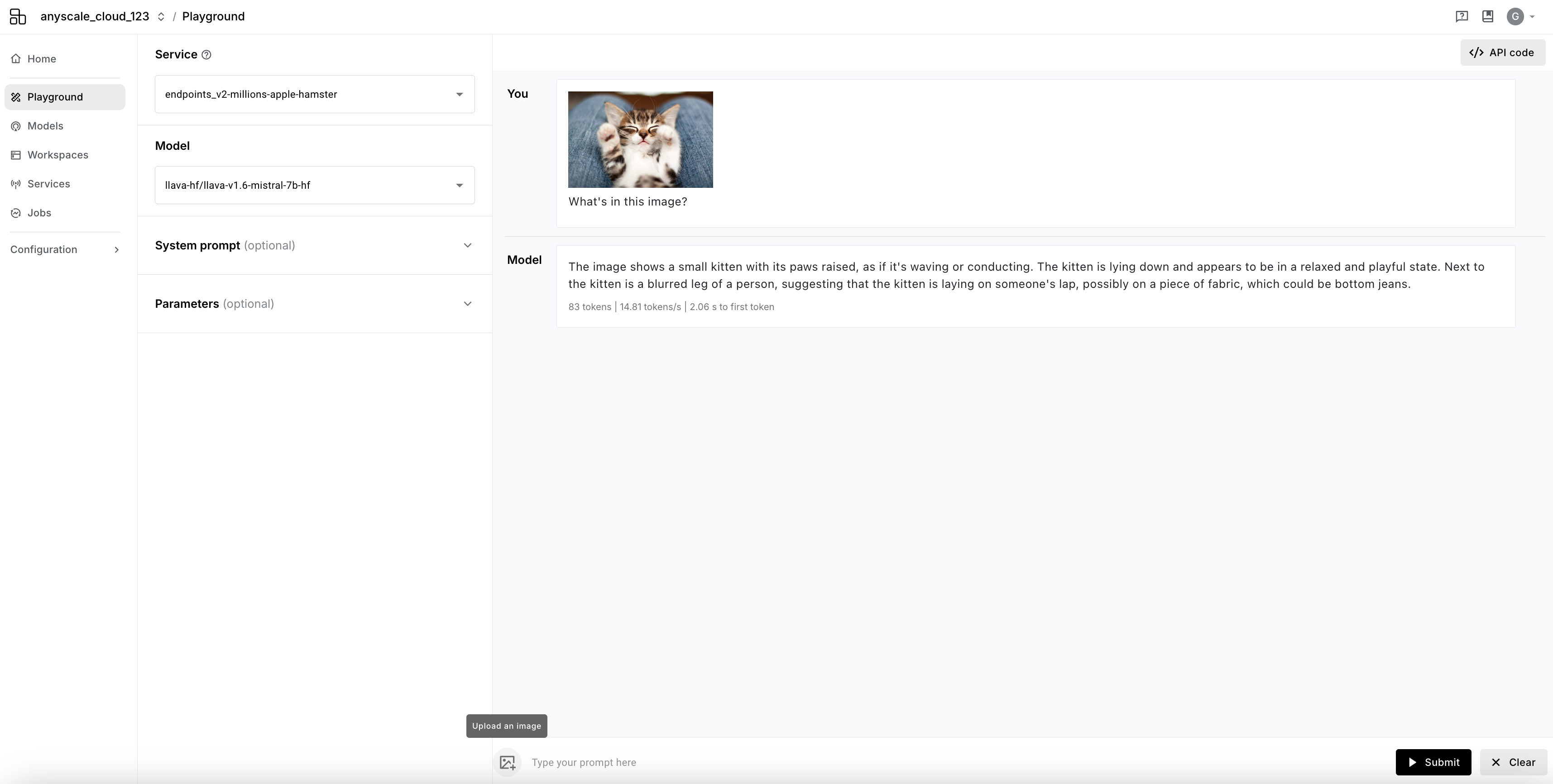
Vision-language models do not support multi-turn conversations. You will not be able to further query the model based on its response.