Storage and file management
Workspace provides different storage options optimized for different use cases, such as speed, level of access, and level of persistence.
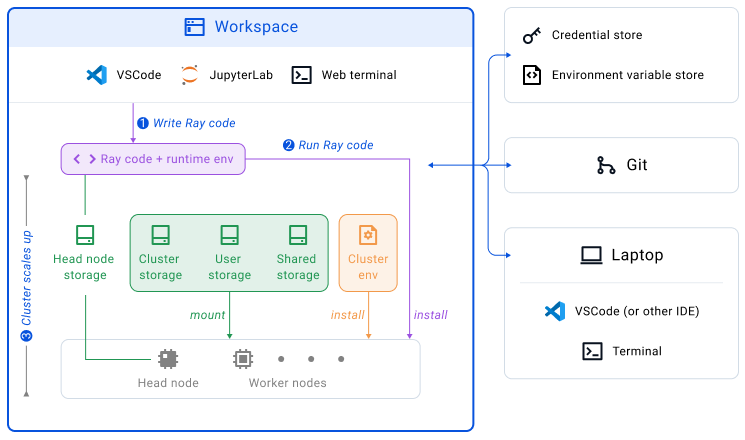
Types of storage options
Local storage for a Node
Each node has its own volume and disk that is not shared with other nodes. Learn more about how to configure the local storage.
Head node storage
This is the file system of the Head Node of your Workspace. Because Workspace development tools are hosted on the head node of the cluster, you can use the Web Terminal and the IDEs to easily manage/edit files stored here. This storage is very fast. Files in your project directory (/home/ray/<your_project_name>) are persisted across Workspace restarts except those ignored by .gitignore. This is also the default directory of the Web Terminal.
Files on the head node file system outside the project directory will be lost after the Workspace is terminated.
NVMe support
/mnt/local_storage - Non-Volatile Memory Express (NVMe) interface to access SSD storage volumes. It provides additional temporary storage to the Node's root disk/volume. This enables higher performance, lower latency, scalability and support for versatile use cases across a variety of workloads. For instance types that do not have NVMe, /mnt/local_storage just falls back to the root disk/volume.
Storage shared across Nodes
A NFS system is set up and mounted automatically on the Workspace/Job/Service Clusters. Learn more about how to configure the shared storage.
Cluster storage
/mnt/cluster_storage - this is a private directory on NFS (for example, AWS EFS, GCP Filestore) mounted on every node of the Workspace cluster and persisted throughout the lifecycle of the Workspace. It is great for storing files that need to be accessible to the Head node and all the Worker nodes. For example:
- TensorBoard logs.
pipdependencies: we recommend using thepip install --userflag so that they are installed to/mnt/cluster_storage/pypiand be made accessible to every Node.
The cluster storage will not be cloned when you clone a Workspace.
User storage
/mnt/user_storage - this is a private directory on NFS (for example, AWS EFS, GCP Filestore) private to the Anyscale user and accessible from every Node of the Workspaces, Jobs and Services Clusters created by the user. It's great for storing files you need to use with multiple Anyscale features.
Shared storage
/mnt/shared_storage - this is a private directory on NFS (for example, AWS EFS, GCP Filestore) accessible to all the Anyscale users of the same Anyscale Cloud. It is mounted on every node of all the Anyscale Clusters in the same Cloud. It is great for storing model checkpoints and other artifacts that you want to share with your team.
Object Storage (S3 or GCS buckets)
For every Anyscale Cloud, a default object storage bucket is configured during the Cloud deployment. All the Workspaces, Jobs, and Services Clusters within an Anyscale Cloud have permission to read and write to its default bucket.
Anyscale writes system- or user-generated files (for example, log files) to this bucket. Do not delete or edit the Anyscale-managed files, which may lead to unexpected data loss. Use $ANYSCALE_ARTIFACT_STORAGE to separate your files from Anyscale-generated files.
Use the following environment variables to access the default bucket:
ANYSCALE_CLOUD_STORAGE_BUCKET: the name of the bucket.ANYSCALE_CLOUD_STORAGE_BUCKET_REGION: the region of the bucket.ANYSCALE_ARTIFACT_STORAGE: the URI to the pre-generated folder for storing your artifacts while keeping them separate them from Anyscale-generated ones.- AWS:
s3://<org_id>/<cloud_id>/artifact_storage/ - GCP:
gs://<org_id>/<cloud_id>/artifact_storage/
- AWS:
How to choose the storage
The choice depends on the expected performance, file sizes, collaboration needs, security requirements, etc.
- NFS is in general slower than the Head node Storage.
- DO NOT put large files like datasets at terabyte scale in NFS storage. Use object storage (like an S3 bucket) for large files (more than 10 GB).
- If you want to share small files across different Workspaces, Jobs, or even Services, user and shared storage are good options.
NFS storage usually has connection limits. Different Cloud Providers may have different limits. Check out the limits and contact support team if you need assistance.
To increase the capacity of GCP Filestore instances, please refer to the GCP documentation.
Upload and download files
- The easiest way to transfer small files to and from your Workspace is to use the JupyterLab UI (click
uploadordownloadbutton in the file explorer). - You can also commit files to git and run
git pullfrom the Workspace. - For large files, the best practice is to use object storage (for example, Amazon S3 or Google Cloud Storage) and access the data from there.
Configure storage for ML workloads
When running ML training or tuning workloads in Workspaces, it may be useful to store your training or tuning results in /mnt/cluster_storage or /mnt/shared_storage by setting the storage_path in RunConfig (example). This allows the results to be persisted across time and even shared with other collaborators.