Debugging Ray Data auto-scaling errors
Debugging Ray Data auto-scaling errors
This document is part of a series of debugging tips for the most common Ray + Anyscale errors. It leverages Anyscale's observability suite to identify the root causes of issues. Each error has a real code example to demonstrate the debugging process. These steps are also applicable to other applications encountering similar errors.
This guide specifically focuses on troubleshooting Ray Data auto-scaling errors, typically indicated by the following exception message: ray.exceptions.ActorUnschedulableError: The actor is not schedulable
Example
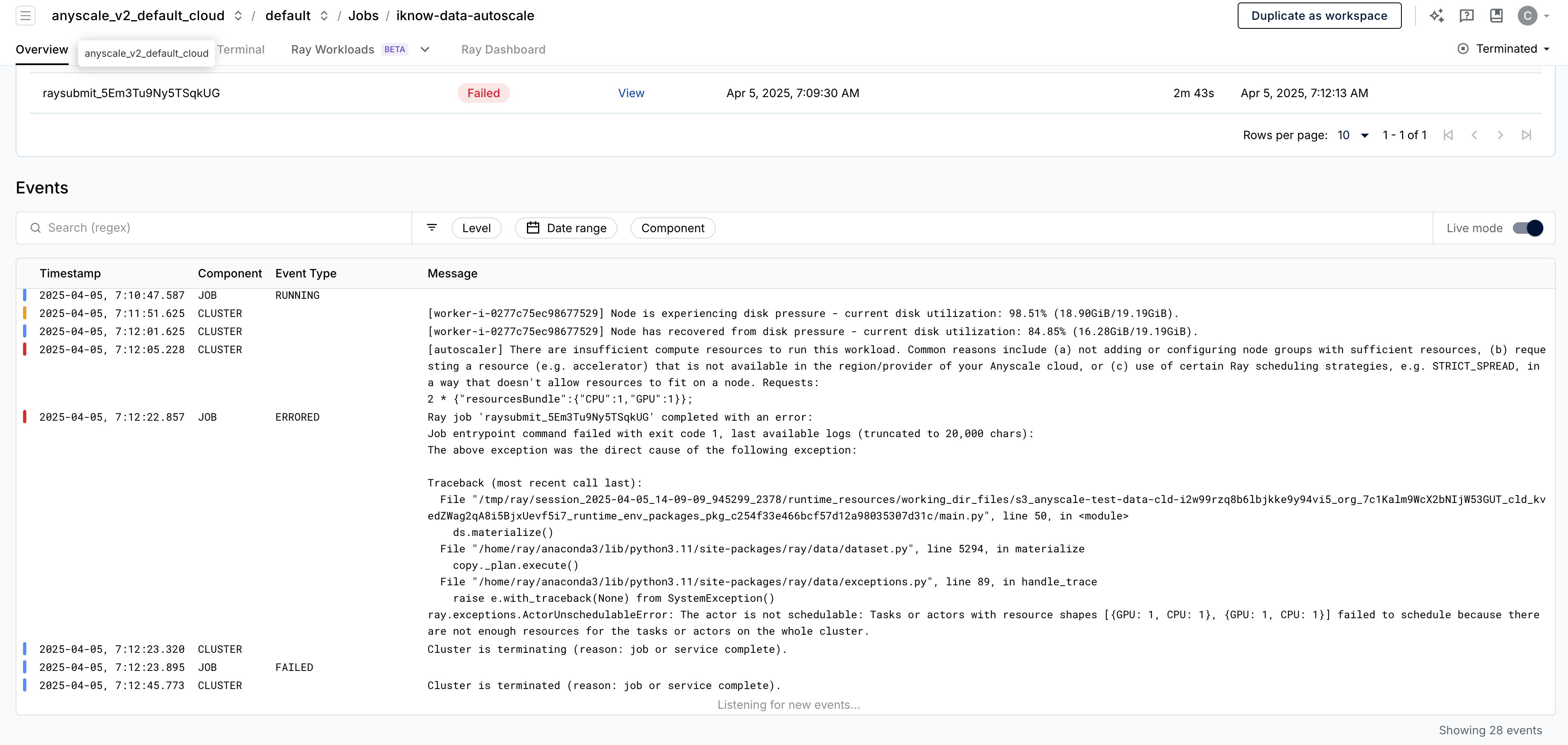
The job prodjob_idpsahqledl73vynziiz7skbl2 failed on Apr 5, 2025, 7:12:13 AM due to the following error:
File "/tmp/ray/session_2025-04-05_14-09-09_945299_2378/runtime_resources/working_dir_files/s3_anyscale-test-data-cld-i2w99rzq8b6lbjkke9y94vi5_org_7c1Kalm9WcX2bNIjW53GUT_cld_kvedZWag2qA8i5BjxUevf5i7_runtime_env_packages_pkg_c254f33e466bcf57d12a98035307d31c/main.py", line 50, in <module>
ds.materialize()
File "/home/ray/anaconda3/lib/python3.11/site-packages/ray/data/dataset.py", line 5294, in materialize
copy._plan.execute()
File "/home/ray/anaconda3/lib/python3.11/site-packages/ray/data/exceptions.py", line 89, in handle_trace
raise e.with_traceback(None) from SystemException()
ray.exceptions.ActorUnschedulableError: The actor is not schedulable: Tasks or actors with resource shapes [{GPU: 1, CPU: 1}, {GPU: 1, CPU: 1}] failed to schedule because there are not enough resources for the tasks or actors on the whole cluster.
Step 1: Confirm the auto-scaling error
To verify whether the job failure is due to an auto-scaling issue, check the cluster error logs around the failure time. In this example, approximately 5 minutes before the error occurred, the following cluster auto-scaling log appears. Note the timestamp of this event: Apr 5, 2025, 7:12:05 AM.
[autoscaler] There are insufficient compute resources to run this workload. Common reasons include (a) not adding or configuring node groups with sufficient resources, (b) requesting a resource (e.g. accelerator) that is not available in the region/provider of your Anyscale cloud, or (c) use of certain Ray scheduling strategies, e.g. STRICT_SPREAD, in a way that doesn't allow resources to fit on a node. Requests:
2 * {"resourcesBundle":{"CPU":1,"GPU":1}};
Step 2: Identify the culprit task
To pinpoint the task causing the issue, use the Ray Core Grafana dashboard available on the Anyscale platform. Run a PromQL query to identify the task that was pending for node assignment near the error timestamp: Apr 5, 2025, 7:12:05 AM.
Update the ClusterId field in the query, which you can find in the Ray Core Grafana dashboard:
sum(ray_tasks{State="PENDING_NODE_ASSIGNMENT",ClusterId=~"<YOUR_CLUSTER_ID>"}) by (Name)
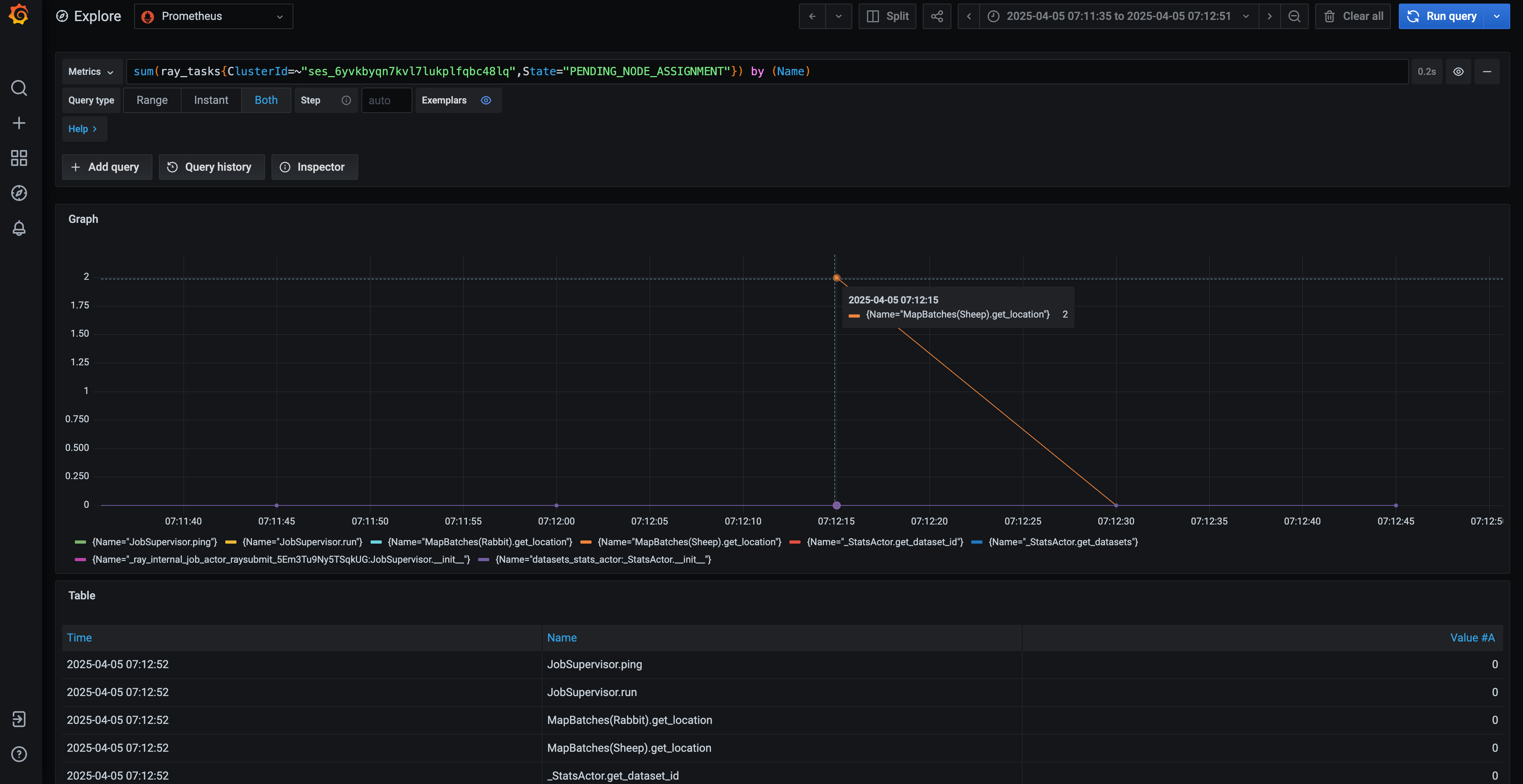
In this case, the only task pending node assignment or auto-scaling at the time of the error was MapBatches(Sheep).get_location. Note that while MapBatches and get_location are internal Ray Data tasks and actors, Sheep is a user-defined actor. This provides some insight into how users might resolve the issue in their programs. Specifically, in this case, the map batches were configured with the following setting:
ray.data.from_numpy(...)
.map_batches(
Rabbit,
concurrency=1,
)
.map_batches(
Sheep,
concurrency=2,
batch_size=4,
num_gpus=1, # problematic resource requests
)
.map_batches(
Pig,
concurrency=1,
)
Based on the investigation, you can confidently conclude the following:
- The task
MapBatches(Sheep).get_locationis the primary cause of the auto-scaling error. - Each task requires 1 CPU and 1 GPU, so with concurrency=2, the total requirement is 2 CPUs and 2 GPUs. This exceeds the available resources in the cluster.
- To resolve the issue, consider either relaxing the task's resource requirements or increasing the resources allocated to the cluster.