LLMForge is being deprecated: The Ray Team is consolidating around open source fine-tuning solutions. Llama Factory and Axolotl provide enhanced functionality (quantization, advanced algorithms) and native Ray support for scaling. See the migration guide for transitioning your workflows.
Choosing cluster shape and DeepSpeed ZeRO stage
Selecting the best compute configuration for distributed training of large models isn't a simple task - cheaper GPUs may not necessarily result in overall lower-cost training runs, depending on factors like model size and ZeRO stage when using DeepSpeed. This user guide covers how to account for important cost and speed considerations, as well as how to address potential pitfalls when fine-tuning LLMs using LLMForge.
Overall guidelines
- Consider cost savings with faster hardware. Cheaper nodes can sometimes result in more expensive training runs than more expensive per-hour nodes due to both GPU speed and communication costs tied to the node specifications.
- Use ZeRO-2 (or lower stages) when you can fit the whole model onto a single GPU, because you can avoid the overhead of passing around model parameters when possible, even on nodes with NVLink. ZeRO-2 is especially useful with LoRA due to low communication costs for optimizer states and gradients.
- Use ZeRO-3 for larger models that don't fit in GPU memory, for example Llama 70B.
- For multi-node training involving just a few nodes, consider using hierarchical partitioning to reduce inter-node communication.
- Intra-node bandwidth can sometimes be a bottleneck for single nodes without NVLink for GPU-GPU communication, especially when using ZeRO-3 with 8 GPUs. Benchmarking bandwidth using NCCL tests is helpful for understanding system limitations.
Cluster shape
The number of nodes and number of GPUs per node can have a large impact on performance during distributed training. The config below doesn't exactly specify a cluster shape. It requests 8 A10G GPUs, which can mean 8 nodes each with 1 A10G, 1 node with 8 A10Gs, or 2 nodes each with 4 A10Gs.
num_devices: 8
...
worker_resources:
accelerator_type:A10G: 0.001
...
To easily specify cluster shapes directly from fine-tuning configs, set anyscale/accelerator_shape instead of just accelerator_type:A10G in worker_resources. The example below requests only nodes specifically with 8xA10Gs for fine-tuning. Note that you must still set num_devices appropriately.
num_devices: 8
...
worker_resources:
anyscale/accelerator_shape:8xA10G: 0.001
...
More details for understanding how different cluster shapes can impact fine-tuning performance are below.
ZeRO stage
- Stage 0
- Stage 1
- Stage 2
- Stage 3
Description: This stage represents the baseline without any memory optimizations. All optimizer states, gradients, and parameters are fully replicated across all GPUs.
Description: Partitions the optimizer states across GPUs. This reduces memory consumption by distributing the optimizer states, which include variables like momentum and variance for the Adam optimizer.
Benefits: Reduces memory usage but not as significantly as higher stages. Suitable for models where optimizer states are a major memory bottleneck.
Description: Extends Stage 1 by also partitioning gradients across GPUs. This further reduces memory usage by distributing both optimizer states and gradients.
Benefits: Provides more significant memory savings compared to Stage 1. It's more efficient and often at parity with Distributed Data Parallel (DDP) due to optimized communication protocols.
Description: The most advanced stage, which partitions optimizer states, gradients, and model parameters across GPUs. This stage can also optionally shard activations.
Benefits: Allows for massive scaling, enabling the training of models with over 40 billion parameters on a single node and over 2 trillion parameters on 512 GPUs. It provides the highest memory efficiency and is essential for extremely large models.
Additional features:
- ZeRO-Offload: Allows offloading optimizer states and gradients to CPU or NVMe, further reducing GPU memory usage. This capability is particularly useful for training very large models on limited GPU resources.
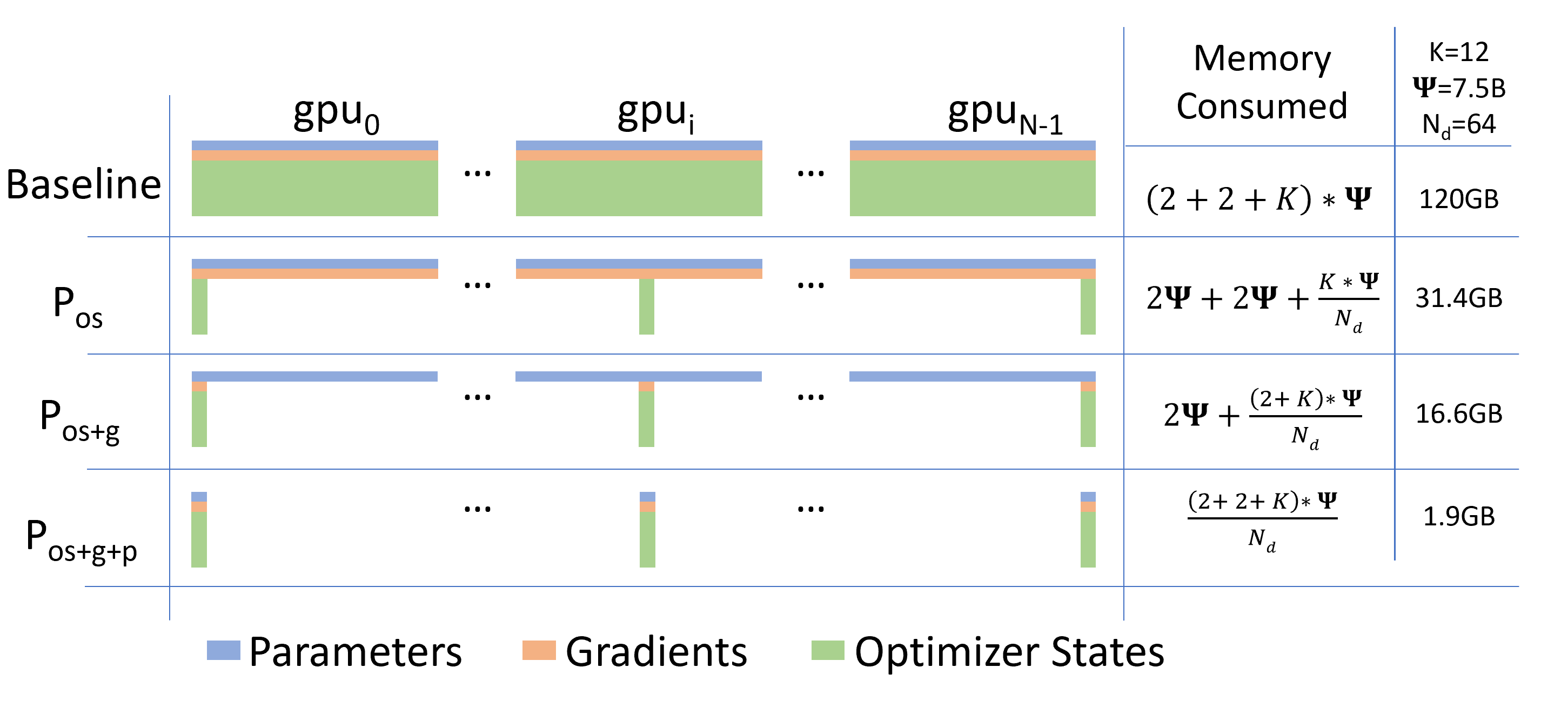
When using DeepSpeed for distributed training, choosing the appropriate ZeRO stage is key for optimizing for training speed and throughput. For models with weights that don't fit on a single GPU, ZeRO stage 3 is the only option. Additionally, if running into OOM errors, enabling offloading gradients and optimizer states to CPU can help free up memory. However, for smaller models that can fit on a single GPU, lower ZeRO stages can often result in higher throughput and training speeds. Below is an example where this is the case for Llama-3-8B.
ZeRO with full fine tuning vs LoRA
Full-parameter fine-tuning and LoRA result in very different communication profiles, and thus different training speeds, especially when using later stages of ZeRO with DeepSpeed. For full-parameter fine-tuning, storing gradient and optimizer states both require as much or more memory than storing model parameters. However, for LoRA, which only tunes a small set of parameters, the gradient and optimizer states are only stored and communicated for that subset of parameters, resulting in greatly reduced memory and communication requirements when using ZeRO-1 or ZeRO-2 compared to the full-parameter fine-tuning case. Thus, the additional communication costs incurred by switching from ZeRO-3 to ZeRO-2 are much more dramatic for LoRA than for full-parameter fine-tuning.
Case study: Llama-3-8B LoRA
A common use case starts with the example in the fine-tuning template. In this example, a Llama-3-8B model is fine-tuned on the GSM8K dataset with LoRA adapters. For benchmarking purposes, modify the template config to fix context length at 1024, pad to the max length, use 8 GPUs, and use DeepSpeed ZeRO stage 3, resulting in the following training config:
num_devices: 8
deepspeed_config: configs/zero_3.yaml # DeepSpeed JSON config docs: https://www.deepspeed.ai/docs/config-json/
worker_resources:
accelerator_type:A10G: 0.001
Cluster shape
Consider three different compute configurations that all could satisfy the preceding requirement of providing 8 A10G GPUs: 1 node of 8 A10Gs, 2 nodes with 4 A10Gs each, or 8 nodes, each with 1 A10G. Additional results for different configurations of L4 GPUs are included for comparison. The results are for G5 nodes from AWS for A10Gs, and G6 nodes for L4s.

Notice that when you use DeepSpeed ZeRO-3, which shards model states in addition to optimizer states and gradients across all ranks, the cluster shape that results in the fastest training time per epoch is with 2 nodes containing 4 GPUs each, rather than a single node with 8 GPUs. Although this might be counterintuitive considering the introduction of internode communication, this improvement in speed is due to bottlenecks from G5 and G6 nodes relying on PCIe for GPU-GPU communication on the same node.
You can diagnose this bottleneck by benchmarking the bus bandwidth of different node configurations on AWS G5 instances using collective communication cost benchmarks from EleutherAI.
| Cluster Shape | Bus Bandwidth (1MB) | Bus Bandwidth (1GB) | Bus Bandwidth (4GB) |
|---|---|---|---|
| 8x1 A10G (g5.4xlarge) | 3.0 GB/s | 22.2 GB/s | 23.0 GB/s |
| 2x4 A10G (g5.12xlarge) | 10.1 GB/s | 26.0 GB/s | 26.2 GB/s |
| 1x8 A10G (g5.48xlarge) | 24.2 GB/s | 13.0 GB/s | 10.2 GB/s |
| 1x8 H100 (w/ NVSwitch) | 450.3 GB/s | 2888.0 GB/s | 2936.0 GB/s |
These benchmark results show that past a certain message size, the intra-node GPU network for a single node of 8 A10Gs becomes a bottleneck, and the offloading of some communication to the interconnect between nodes when using 2 nodes of 4 GPUs actually speeds up communication. The table includes all reduce results on an 8xH100 node with NVSwitch GPU-GPU interconnect for reference.
ZeRO stage
The high communication cost of ZeRO-3 may lead you to consider whether a different ZeRO stage might be beneficial for training on nodes without NVLink. This cost is especially important because you're training with LoRA, which has lower communication costs associated with both gradients and optimizer states. Below are results switching from ZeRO-3 to ZeRO-2, which removes the need to communicate the full model parameters across ranks.

Using ZeRO-2 for LoRA training results in a significant speed up of up to 3x over ZeRO-3, and that ZeRO-2 speeds are more consistent across cluster shapes, because you're no longer bottlenecked by intra-node PCIe bandwidth. In general, use ZeRO-2 over ZeRO-3 when model sizes can fit in memory with a reasonable batch size or sequence length.
Accelerator type

Another consideration is switching to different hardware accelerator and node types. The table above compares training speed and cost between an 8xA10G node, 8xL4 node (both with just PCIe), and an 8xH100 node with NVSwitch. For both ZeRO-2 and ZeRO-3 settings, the H100 node is significantly faster (~4x for ZeRO-2, and up to ~9x over A10Gs for ZeRO-3), and the H100s are actually cheaper to train on, based on an example of AWS on-demand pricing, compared to the cheaper per hour A10Gs.
Cluster shape details
Intra-node communication
PCIe, along with NVLink/NVSwitch, are commonly used technologies for allowing for high bandwidth communication between GPUs on the same node. When training models that don't fit on a single GPU using high communication strategies like DeepSpeed ZeRO stage 2 or 3, GPU-GPU communication within nodes can actually become a bottleneck that affects performance.
This bottleneck can be particularly noticeable on nodes that rely on the lower bandwidth PCIe for GPU-GPU communication, as various device topologies can result in bottlenecks such as communication across Non-uniform memory access, or NUMA, nodes, or overloading of the PCIe host bridge. For example, the AWS G6 instance shown below contains 2 NUMA nodes, with GPUs 0-3 belonging to NUMA node 0, and GPUs 4-7 belonging to NUMA node 1, resulting in inter-GPU communication potentially needing to additionally traverse between the NUMA nodes.
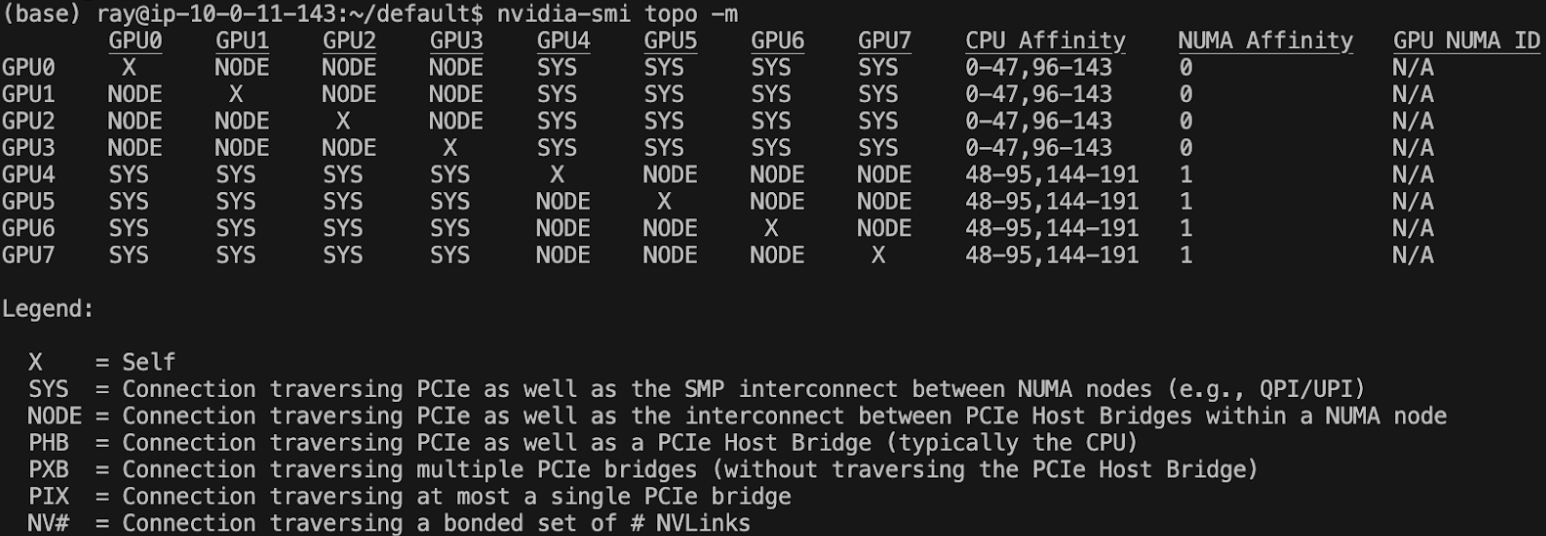
These bottlenecks are less common for nodes using NVLink or NVSwitch for inter-GPU communication, due to their overall higher bandwidth. On AWS, only P3, P4, and P5 nodes, which use V100, A100, and H100 GPUs respectively, use NVLink for GPU-GPU peer to peer communication. However, V100 GPUs don't support optimized kernels like FlashAttention-2, which are more important for training speedups, making A100s and H100s the primary choices for computationally expensive distributed training workloads.
Inter-node communication
Inter-node communication can also be a significant bottleneck when node to node interconnects are much slower than intra-node connections, which is often the case for nodes using NVLink/NVSwitch. Scaling to larger numbers of GPUs and nodes can require increasing to InfiniBand connections for reasonable throughput. One way you can partially mitigate this requirement when using ZeRO stage 3 is by hierarchical partitioning of model parameters using ZeRO++, which maintains a full set of model weights on each machine to reduce the number of cross machine all gather operations. The example below shows how to enable hierarchical partitioning in DeepSpeed by setting zero_hpz_partition_size to the number of GPUs per node.
...
zero_optimization: {
stage: 3,
...
zero_hpz_partition_size: 8,
...
}
...
Use hierarchical partitioning only on nodes with NVLink, because the speedup relies on intra-node bandwidth being much higher than inter-node bandwidth. The table below shows the difference in throughput for fine-tuning a Llama-3-8B model with and without hierarchical partitioning for AWS G5 nodes, which use PCIe, and for AWS P3 nodes, which use NVLink. Hierarchical partitioning results in a speed up for the P3 nodes, but in relatively lower throughput for G5 nodes due to their use of lower bandwidth PCIe.
| Cluster Shape | ZeRO-3 Throughput | ZeRO-3 + HPZ Throughput |
|---|---|---|
| 2x4 A10G (g5.12xlarge) | 2416 tokens/s | 1842 tokens/s |
| 2x4 V100 (p3.8xlarge) | 798 tokens/s | 1491 tokens/s |
Communication benchmarking
To understand the limitations and bottlenecks of a given cluster setup for distributed training you can benchmark common communication methods across all ranks. The following resources are helpful for a quick way to get started with benchmarking.
The benchmark above uses the Eleuther cookbook to help profile the difference between two different cluster setups.