Deploy scalable MCP servers with Ray Serve
Deploy scalable MCP servers with Ray Serve
Transform local Model Context Protocol (MCP) servers into production services on Anyscale using Ray Serve. This guide covers transport protocols, statelessness, ingress configuration, autoscaling, resource allocation, observability, high availability, authentication, and validation.
Why use Ray Serve and Anyscale services for MCP deployment
Ray Serve provides the following advantages when you deploy MCP:
- Automatic scaling: Adjusts replicas based on traffic to meet demand.
- Load balancing: Distributes requests across healthy replicas.
- Fault tolerance: Restarts failed replicas and shifts traffic automatically.
- Built-in monitoring: Exposes metrics for requests and performance.
On Anyscale, you also get:
- Production infrastructure: Managed deployment, networking, and upgrades.
- High availability: Multi-zone scheduling and zero-downtime updates.
- Enhanced observability: Centralized logs and distributed traces. See Tracing guide and Custom dashboards and alerting.
- Head node resilience: Managed redundancy for cluster coordination.
Get started
To deploy MCP servers on Anyscale, use the MCP template notebook. See Anyscale MCP template.
Architecture
The following example integrates the weather MCP server with Ray Serve and Anyscale services. This design runs a custom MCP service for weather on Ray Serve, deployed as an Anyscale service. A large language model (LLM) or agent client sends requests to a FastAPI app that embeds a remote MCP server (streamable over HTTP). The server exposes tools such as get_alerts and get_forecast. These tools call external data sources (for example, the National Weather Service at api.weather.gov) and stream results back to the client.
Ray Serve provides the serving layer with autoscaling, load balancing, observability, and fault tolerance. Anyscale hardens the deployment for production with high availability, centralized logging and tracing, and head node fault tolerance.
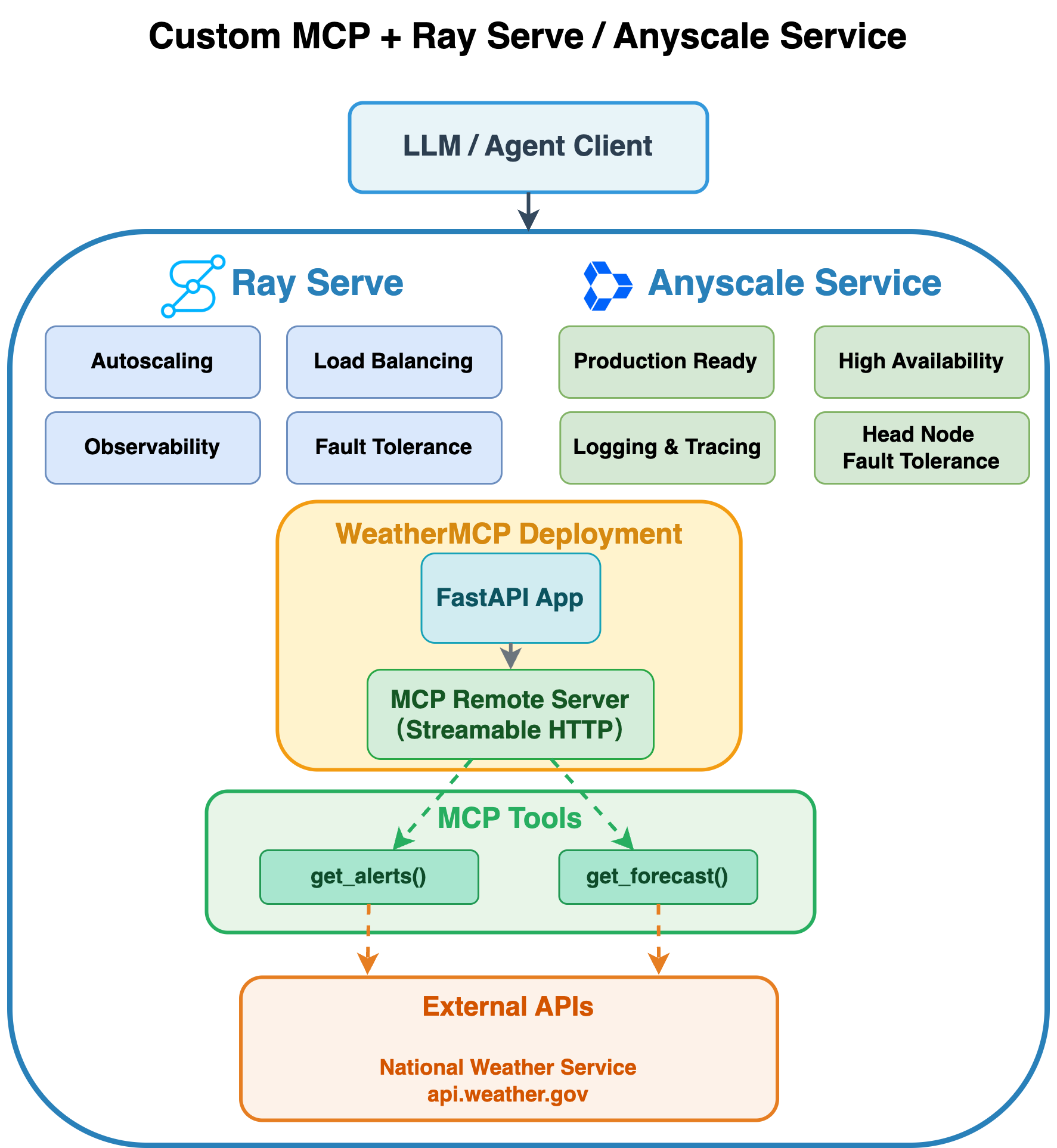
The following sections describe the core components and concepts in the architecture:
1. Streamable HTTP transport
Streamable HTTP enables MCP servers to run remotely. For an overview of MCP transport protocols, see Transport mechanisms.
You must use stateless mode for MCP servers. Otherwise, you encounter "session not found" errors when you deploy multiple MCP server replicas.
from mcp.server.fastmcp import FastMCP
mcp_app = FastMCP("your-mcp-server", stateless_http=True)
2. Integration with FastAPI
Expose your MCP server through a FastAPI application and mount the streamable HTTP app at /mcp (default path). Use Ray Serve ingress to bind this FastAPI app as the HTTP interface for your deployment. FastAPI handles path matching, extracts path and query parameters, performs data validation, and serializes your tool's return value into HTTP responses. As a result:
- Your service exposes an MCP endpoint at
/mcp. - Ray Serve manages health checks and routes requests across replicas automatically.
For streamable HTTP transport, you must pass the lifespan context from the FastMCP server to the FastAPI app with FastAPI(lifespan=mcp_app.lifespan) to ensure the server's session manager initializes properly.
3. Autoscaling configuration
Configure autoscaling to balance latency, throughput, and cost:
- Set replica limits: Configure minimum and maximum replicas for capacity planning.
- Define load targets: Set
target_ongoing_requestsrequests per replica to trigger scale events. - Use fractional CPUs and GPUs: Allocate fractional compute resources (0.25 CPU or 0.5 GPU) to improve utilization.
For detailed configurations, see Ray Serve autoscaling and Resource allocation.
4. Observability
Use Anyscale monitoring to view logs, traces, and metrics across replicas:
- Structured logs: View logs per request and per replica.
- Distributed tracing: Trace requests end-to-end across services.
- Performance metrics: Track request rate, latency, and error rates to tune autoscaling.
For details, see Accessing logs and Tracing guide.
5. Authentication and security
Production services require authentication and network controls:
- Bearer token authentication: Anyscale enables bearer tokens for all services by default. Pass an
Authorization: Bearer <token>header from the client when you call the MCP endpoint. - Service URL: Use the URL that Anyscale assigns and include the
/mcppath when you make requests.
Deploy MCP services with GPUs
When MCP tools run machine learning inference, provision GPUs for each replica:
- Fractional GPUs: Allocate partial GPUs (for example, 0.5) to increase utilization when models are small.
- Runtime environment: Include machine learning dependencies in the service image to speed startup.
- Concurrency: Offload blocking model calls to worker threads or processes to keep event loops responsive.
For a GPU-backed example, see the translator service in the Anyscale template. See Translator MCP example.
Use fractional GPUs to balance cost and throughput when your model doesn't require a full GPU.
MCP gateway for Ray Serve on Anyscale
The MCP gateway provides a unified, streamable HTTP interface for tools and agents. Ray Serve applications (for example, image classification or translation) run independently behind it. An Anyscale service hosts the deployment with managed scaling, fault tolerance, and rolling updates.
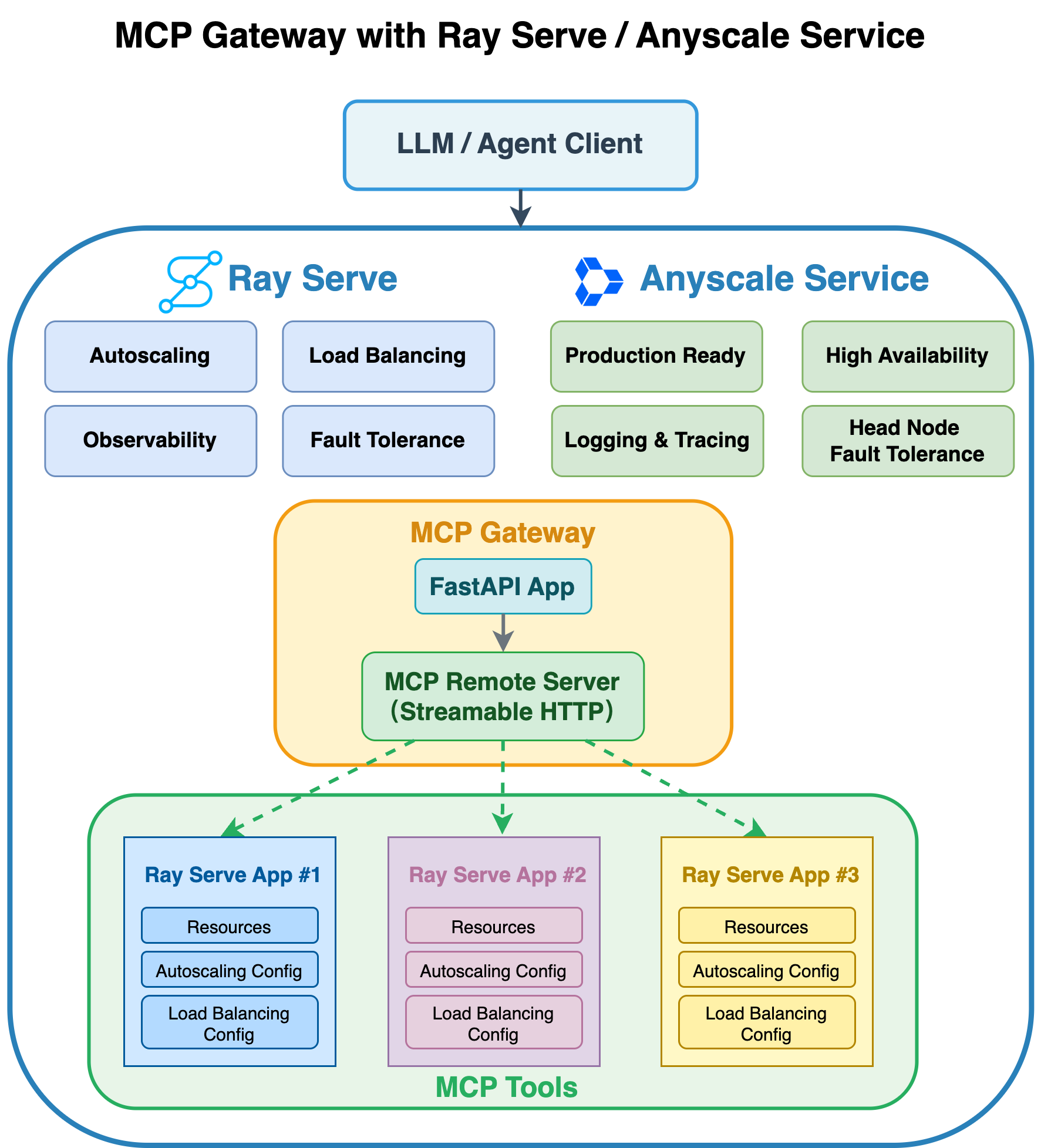
Why use an MCP gateway?
- Unify access: Expose multiple Ray Serve apps as a single remote MCP service through one streamable HTTP endpoint for tools and agents.
- Preserve autonomy: Keep independent scaling, resource allocation, and rollout policies per Serve app.
- Avoid code merges: Keep your existing app repositories unchanged while adding an MCP front-end.
- Operate as a service: Deploy on Anyscale services with managed scaling, availability, and updates.
Get started with MCP gateway
To deploy MCP gateway on Anyscale, use the MCP template notebook. See Anyscale MCP template.